集合框架
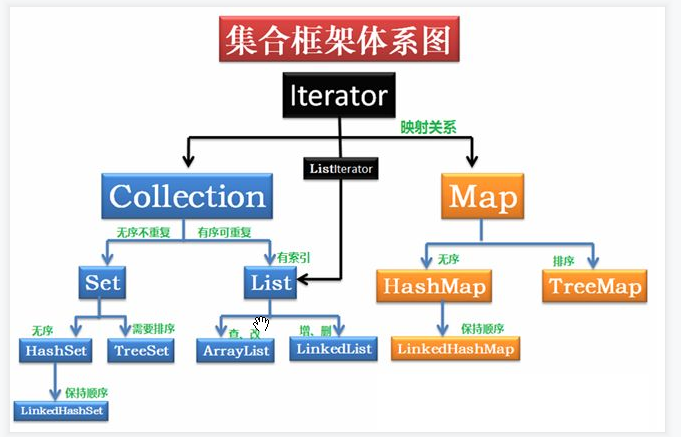
1:集合:(1) Collection(单列集合)List(有序,可重复)ArrayList底层数据结构是数组,查询快,增删慢 线程不安全,效率高Vector 底层数据结构是数组,查询快,增删慢 线程安全,效率低LinkedList 底层数据结构是链表,查询慢,增删快 线程不安全,效率高Set(无序,唯一)HashSet 底层数据结构是哈希表。 哈希表依赖两个方法:hashCode()和equals()
LinkedHashSet底层数据结构由链表和哈希表组成。 由链表保证元素有序。 由哈希表保证元素唯一。TreeSet 底层数据结构是红黑树。(是一种自平衡的二叉树) 如何保证元素唯一性呢? 根据比较的返回值是否是0来决定 如何保证元素的排序呢? 两种方式 自然排序(元素具备比较性) 让元素所属的类实现Comparable接口 比较器排序(集合具备比较性) 让集合接收一个Comparator的实现类对象
(2)Map(双列集合)A:Map集合的数据结构仅仅针对键有效,与值无关。 B:存储的是键值对形式的元素,键唯一,值可重复。 HashMap 底层数据结构是哈希表。线程不安全,效率高 哈希表依赖两个方法:hashCode()和equals() 执行顺序: 首先判断hashCode()值是否相同 是:继续执行equals(),看其返回值 是true:说明元素重复,不添加 是false:就直接添加到集合 否:就直接添加到集合 最终: 自动生成hashCode()和equals()即可 LinkedHashMap 底层数据结构由链表和哈希表组成。 由链表保证元素有序。 由哈希表保证元素唯一。Hashtable 底层数据结构是哈希表。线程安全,效率低 哈希表依赖两个方法:hashCode()和equals() 执行顺序: 首先判断hashCode()值是否相同 是:继续执行equals(),看其返回值 是true:说明元素重复,不添加 是false:就直接添加到集合 否:就直接添加到集合 最终: 自动生成hashCode()和equals()即可TreeMap 底层数据结构是红黑树。(是一种自平衡的二叉树) 如何保证元素唯一性呢? 根据比较的返回值是否是0来决定 如何保证元素的排序呢? 两种方式 自然排序(元素具备比较性) 让元素所属的类实现Comparable接口 比较器排序(集合具备比较性) 让集合接收一个Comparator的实现类对象
2:到底使用那种集合:是否是键值对象形式:是:Map键是否需要排序:是:TreeMap否:HashMap 不知道,就使用HashMap。
否:Collection元素是否唯一:是:Set元素是否需要排序:是:TreeSet否:HashSet 不知道,就使用HashSet否:List要安全吗:是:Vector否:ArrayList或者LinkedList增删多:LinkedList 查询多:ArrayList 不知道,就使用ArrayList不知道,就使用ArrayList
Collection接口
Collection 层次结构 中的根接口,单列集合。存储的对象。
目标: Collection集合概述。
什么是集合?
集合是一个大小可变的容器。
容器中的每个数据称为一个元素。数据==元素。
集合的特点是:类型可以不确定,大小不固定。集合有很多种,不同的集合特点和使用场景不同。
数组:类型和长度一旦定义出来就都固定了。
集合有啥用?
在开发中,很多时候元素的个数是不确定的。
而且经常要进行元素的增删改查操作,集合都是非常合适的。
开发中集合用的更多!!
Java 中集合的代表是: Collection.
Collection集合是Java中集合的祖宗类。
学习Collection集合的功能,那么一切集合可以用这些功能!!
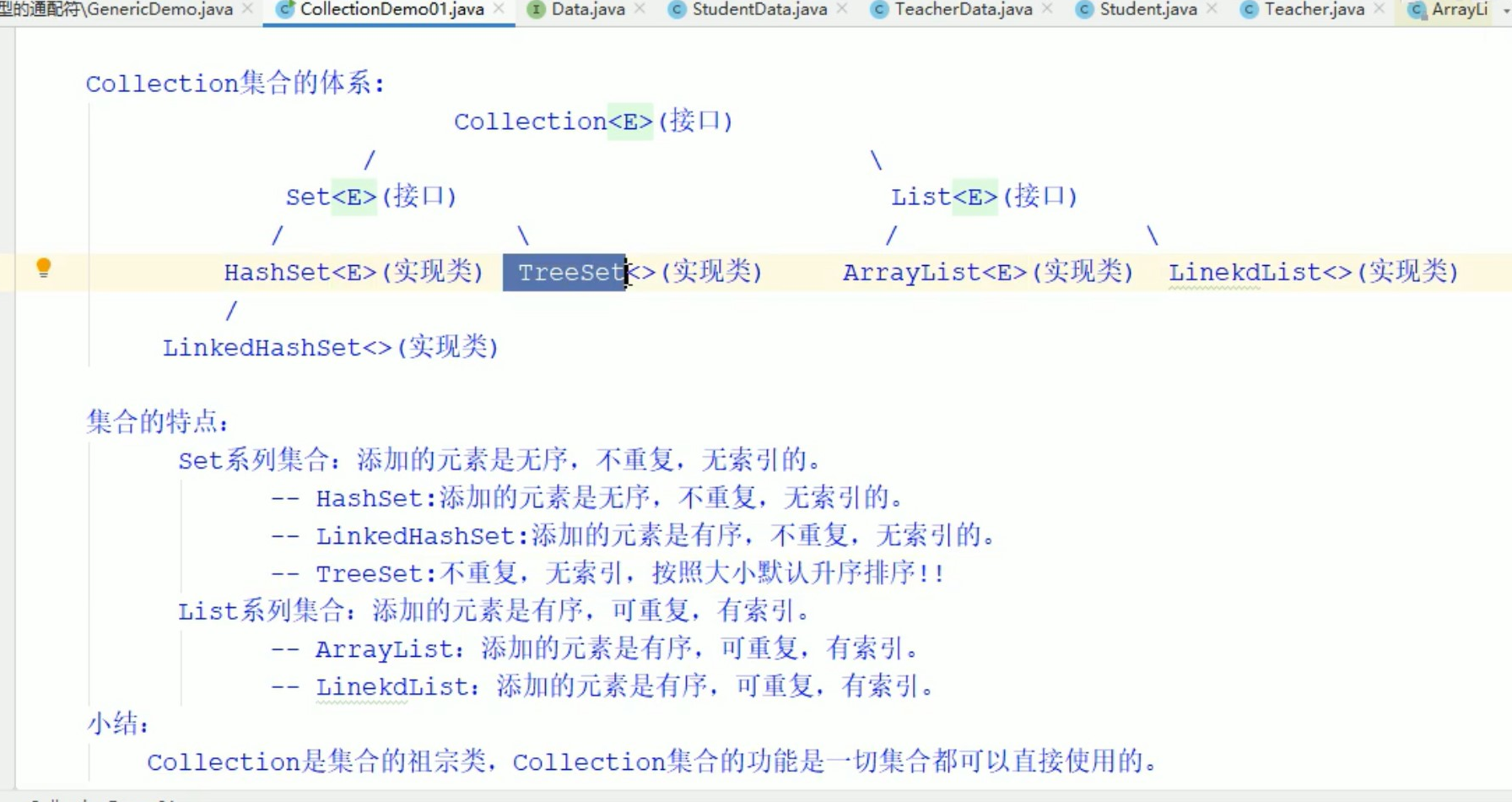
集合的特点:
set系列集合,添加的元素是无序,不重复,无索引的。
—— HashSet: 添加的元素是无序,不重复,无索引的。
—– LinkedHashSet: 添加的元素是有序,不重复,无索引的。
—– TreeSet:不重复,无索引,按照大小默认升序排序!!
List系列集合: 添加的元素是有序,可重复,有索引。
—— ArrayList: 添加的元素是有序,可重复,有索引。
—– LinekdList: 添加的元素是有序,可重复,有索引。
小结:
Collection是集合的祖宗类,Collection集合的功能时一切集合都可以直接使用的。
数组与集合
1.数组可以存储任意数据类型,可以存储基本数据类型也可以存储引用数据类型。 只能存储同一种。
并且在一开始的时候,长度就固定了。对于数组增删操作时,移动的位置会多。
2.集合实质是对数组的一个补充,集合中可以存储任意数据类型的对象。但是不能存储基本数据类型
的数值的,提供了方法,对数据的crud,进行便捷操作。
3.无论是数组还是集合,都是用来存储数据的容器。
集合创建对象
1.Collection 集合体系:
2.集合是一个接口。必须通过子类来创建对象。
构造方法:
① ArrayList()
3.集合常用方法:
① add(E e) 添加
② addAll(Collection< ? extends E> c) 将一个集合中的元素添加到另一个集合。
③ clear() 清除
④ contains(Object o) 判断包含
注意:
判断结果取决于参数的equals方法。对于自定义类来说,要重写equals方法,达到按需求返回true的目的。
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collection;
/**
1.Collection 集合体系:
2.集合是一个接口。必须通过子类来创建对象。
构造方法:
① ArrayList()
3.集合常用方法:
① add(E e) 添加
② addAll(Collection<? extends E> c) 将一个集合中的元素添加到另一个集合。
③ clear() 清除
④ contains(Object o) 判断包含
注意:判断结果取决于参数的equals方法。对于自定义类来说,要重写equals方法,达到按 需求返回true的目的。
*/
public class Collection集合 {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add(true);//Boolean
c.add(123);// Integer
c.add("abc");
c.add(new Person("张三",19));
Collection c1 = new ArrayList();
// ② addAll(Collection<? extends E> c) 将一个集合中的元素添加到另一个集合。
// c1.addAll(c);
// ③ clear() 清除
// c.clear();
// ④ contains(Object o) 判断包含
// System.out.println(c.contains(1234));
System.out.println(c.contains(new Person("张三",19)));
}
}
class Person{
String name;
int age;
public Person() {
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (age != person.age) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Collection
常用方法
1.remove(Object o) 移除 单个元素,多个重复元素,每次只能删除一个
2.size() 相当于length 表示集合中元素个数
3.toArray() 集合转数组 ,返回值的数据类型 Object
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collection;
/**
1.remove(Object o) 移除 单个元素,多个重复元素,每次只能删除一个
2.size() 相当于length 表示集合中元素个数
3.toArray() 集合转数组 ,返回值的数据类型 Object */
public class 集合常用方法 {
public static void main(String[] args) {
Collection c = new ArrayList();
//isEmpty() 判断集合是否为空元素集合,如果是返回true
// System.out.println(c.isEmpty());
c.add(1);
c.add(2);
c.add(3);
c.add(4);
c.add(2);
/* System.out.println(c);
for (int i = 0; i < c.size(); i++) {
c.remove(2);
}System.out.println(c);*/
Object[] arr = c.toArray();
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
}
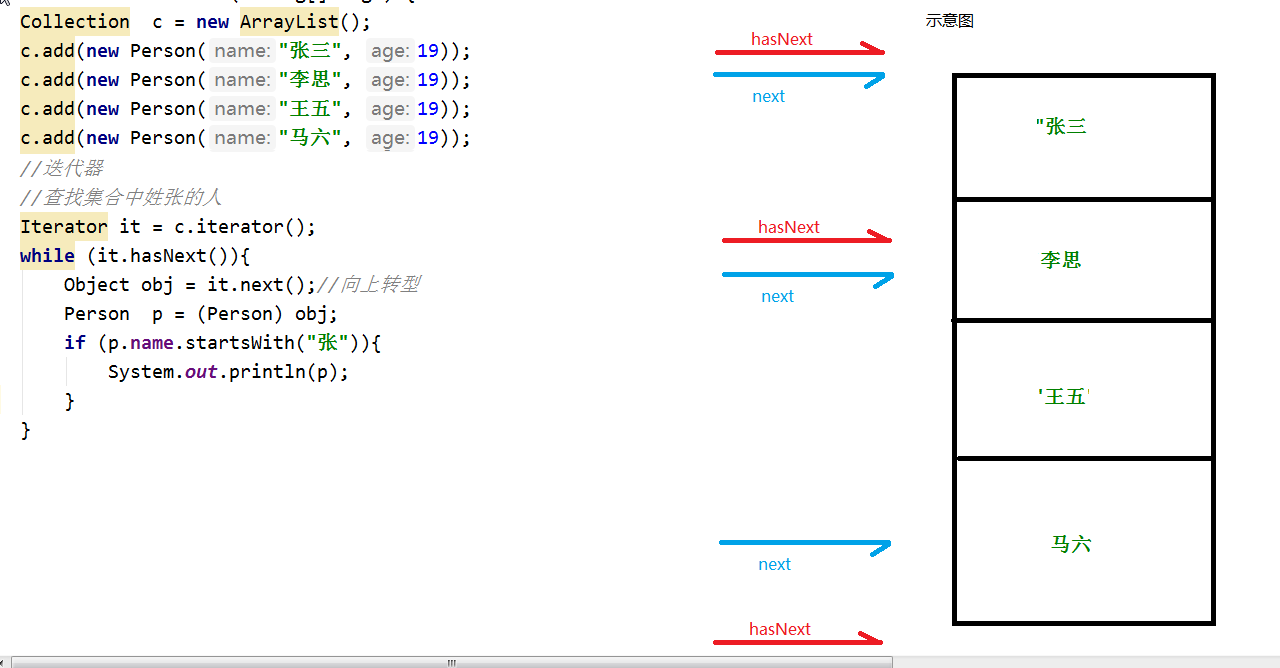
迭代器
1.Iterator :迭代器
① hasNext():判断该位置是否还有集合元素
② next() :返回该集合元素
③ remove() : 删除集合元素
2.获取迭代器的方式:
① iterator()
3.NoSuchElementException 没有该元素异常 ,发生于集合中没有元素,但是通过next方法获取时。
4.建议:
迭代器额hasNext与next方法一配一使用。
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
1.数据操作 :crud 增删改查。
2.Iterator :迭代器
① hasNext():判断该位置是否还有集合元素
② next() :返回该集合元素
③ remove() : 删除集合元素
3.获取迭代器的方式:
① iterator()
4.NoSuchElementException 没有该元素异常 ,发生于集合中没有元素,但是通过next方法获取 时。
*/
public class 迭代器 {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add(1);
c.add("abc");
c.add(true);
c.add('我');
//获取 集合中某个位置的元素 "abc" 遍历
Iterator it = c.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
并发修改异常
1.集合删除元素:
① remove(obj) 集合的删除方法 删除单个元素
② remove() 迭代器的删除
\2. 并发修改异常:ConcurrentModificationException
原因:
当使用集合进行类似于迭代器的遍历时,如果在遍历的过程中,对集合进行了增删操作,就会报该异常。
必须使用迭代器自身的删除方法,才不会有问题。
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
1.集合删除元素:
① remove(obj) 集合的删除方法 删除单个元素
② remove() 迭代器的删除
2. 并发修改异常:ConcurrentModificationException
原因:当使用集合进行类似于迭代器的遍历时,如果在遍历的过程中,对集合进行了增删操作,就会报该异常。
必须使用迭代器自身的删除方法,才不会有问题。 */
public class 集合元素删除的方式 {
public static void main(String[] args) {
Collection c = new ArrayList();
c.add(1);
c.add(2);
c.add(3);
c.add(4);
c.add(5);
Iterator it = c.iterator();
while (it.hasNext()){
Object obj = it.next();
//删除值为3 的元素
if (obj.equals(3)){
it.remove();
// c.remove(3); //建议使用迭代器自身的删除方法而不是集合的删除方法
}
}
System.out.println(c);
}
}
集合的泛型
1.引入泛型:
检测数据类型是否符合要求。
2.格式:
集合的数据类型<要存储的数据类型>
3.集合泛型:
① 将运行期的类型转换异常转变成编译期的异常,提高了程序的健壮性。
② 避免了向下转型。
4.泛型的特点:
① 可擦除技术:泛型只存在编译期,class文件中不存在。
② 菱形技术:1.6必须只能new后的集合对象的泛型的数据类型,但是1.7之后,有了类型推断,根据前面的泛型,可以推导后面的泛型,省略不写。
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
1.引入泛型:
检测数据类型是否符合要求。
2.格式:
集合的数据类型<要存储的数据类型>
3.集合泛型:
① 将运行期的类型转换异常转变成编译期的异常,提高了程序的健壮性。
② 避免了向下转型。
4.泛型的特点:
① 可擦除技术:泛型只存在编译期,class文件中不存在。
② 菱形技术:1.6必须只能new后的集合对象的泛型的数据类型,但是1.7之后,有了类型推断,根据前面的泛型,可以推导后面的泛型,省略不写。
*/
public class 集合的泛型 {
public static void main(String[] args) {
Collection<Student> c = new ArrayList<>();//菱形技术。省略不写泛型的数据类型。
c.add(new Student("张三", 19));
c.add(new Student("李思", 19));
// c.add(1);
// c.add("abc");
// c.add(true);
//使用集合判断如果是学生对象,就调用study方法。
/*Iterator it = c.iterator();
while (it.hasNext()){
Object obj = it.next();
if ( obj instanceof Student){
Student st = (Student) obj;
st.study();
}
}*/
//带有泛型的形式
Iterator<Student> it = c.iterator();
while (it.hasNext()){
Student st = it.next();
System.out.println(st.name);
}
}
}
class Student {
String name;
int age;
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public void study(){
System.out.println("goodgoodstudy");
}
}
List集合
概述
1.有序的集合:
有序:插入与存储顺序相同
(***) 2.List集合特点:
有序 可重复 可插入null
3.List集合可以通过索引访问集合中的元素。
4.常用方法:
① add(int index, E element) 根据index 添加元素
注意:
第一个参数index有范围,从[0,size]范围为止。
(***)② get(int index) 返回index位置的元素
(***)③ listIterator()/listIterator(int index) 获取List集合特有的迭代器
1》 hasPrevious() 向上判断是否存在元素
2》 previous() 获取元素值
④ remove(int index) /remove(Object o) 删除索引/对象元素
注意:
如果是数值,认为是index索引值,如果是想通过数值对象删除,必须通过new操作创建对象。
⑤ set(int index, E element) 修改
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.ListIterator;
/**
1.有序的集合:
有序:插入与存储顺序相同
(***) 2.List集合特点:
有序 可重复 可插入null
3.List集合可以通过索引访问集合中的元素。
4.常用方法:
① add(int index, E element) 根据index 添加元素
注意:
第一个参数index有范围,从[0,size]范围为止。
(***)② get(int index) 返回index位置的元素
(***)③ listIterator()/listIterator(int index) 获取List集合特有的迭代器
1》 hasPrevious() 向上判断是否存在元素
2》 previous() 获取元素值
④ remove(int index) /remove(Object o) 删除索引/对象元素
注意:
如果是数值,认为是index索引值,如果是想通过数值对象删除,必须通过new操作创建对象。
⑤ set(int index, E element) 修改
*/
public class List集合 {
public static void main(String[] args) {
List<Integer> c = new ArrayList<>();
c.add(1);
c.add(5);
c.add(2);
c.add(7);
System.out.println(c);
// ① add(int index, E element) 根据index 添加元素
// c.add(5, 15);
// (***)② get(int index) 返回index位置的元素
// System.out.println(c.get(2));
// ③ listIterator() 获取List集合特有的迭代器
/* ListIterator<Integer> it = c.listIterator(c.size());
*//*while(it.hasNext()){
System.out.println(it.next());
}*//*
while(it.hasPrevious()){
System.out.println(it.previous());
}*/
// ④ remove(int index) /remove(Object o) 删除索引/对象元素
//删除数值为5的元素
// c.remove(new Integer(5));
// ⑤ set(int index, E element) 修改
c.set(1, 17);
System.out.println(c);
}
}
ArrayList集合
概述
(***)1.ArrayList 底层:List 接口的大小可变数组的实现
2.ArrayList 特点: 有序 可重复 可存储null
3.构造方法:
① ArrayList() 初始容量为10的数组
② ArrayList(Collection< ? extends E> c)
代码
package com.demo;
import java.util.ArrayList;
/**
(***)1.ArrayList 底层:List 接口的大小可变数组的实现
2.ArrayList 特点: 有序 可重复 可存储null
3.构造方法:
① ArrayList() 初始容量为10的数组
② ArrayList(Collection<? extends E> c)
*/
public class ArrayList集合 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
System.out.println(list);
list.add("abc");
list.add("def");
ArrayList<String> list1 = new ArrayList<>(list);
System.out.println(list1);
}
}
集合的遍历方式
1.集合的遍历方式:
① 迭代器: Iterator : hasNext next 单列集合通过
② List下特有的接口:只能List集合使用 ListIterator
③ for循环 :只适用于List集合
④ 转数组 toArray()单列集合通过
(***) ⑤ 增强for循环 底层原理:迭代
格式:
for(变量的数据类型 变量的名称: 整体的名称){
}
代码
package com.demo;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
/**
1.集合的遍历方式:
① 迭代器: Iterator : hasNext next 单列集合通过
② List下特有的接口:只能List集合使用 ListIterator
③ for循环 :只适用于List集合
④ 转数组 toArray()单列集合通过
(***) ⑤ 增强for循环 底层原理:迭代
格式:
for(变量的数据类型 变量的名称: 整体的名称){
}
*/
public class 集合的遍历方式 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
// ① 迭代器: Iterator : hasNext next
/* Iterator<Integer> it = list.iterator();
while (it.hasNext()){
System.out.println(it.next());
}*/
// ② List下特有的接口:只能List集合使用 ListIterator
/*ListIterator<Integer> listIt = list.listIterator(list.size());
while (listIt.hasPrevious()){
System.out.println(listIt.previous());
}*/
// ③ for循环 只适用于List集合
/* for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}*/
// ④ 转数组 toArray()单列集合通过
/* Object[] arr = list.toArray();
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
*/
// ⑤ 增强for循环
/* for (Integer it:list) {
System.out.println(it);
}*/
int[] arr2 = {1,2,3,4,5,6};
for(int i:arr2){
System.out.println(i);
}
}
}
LinkedList
结构
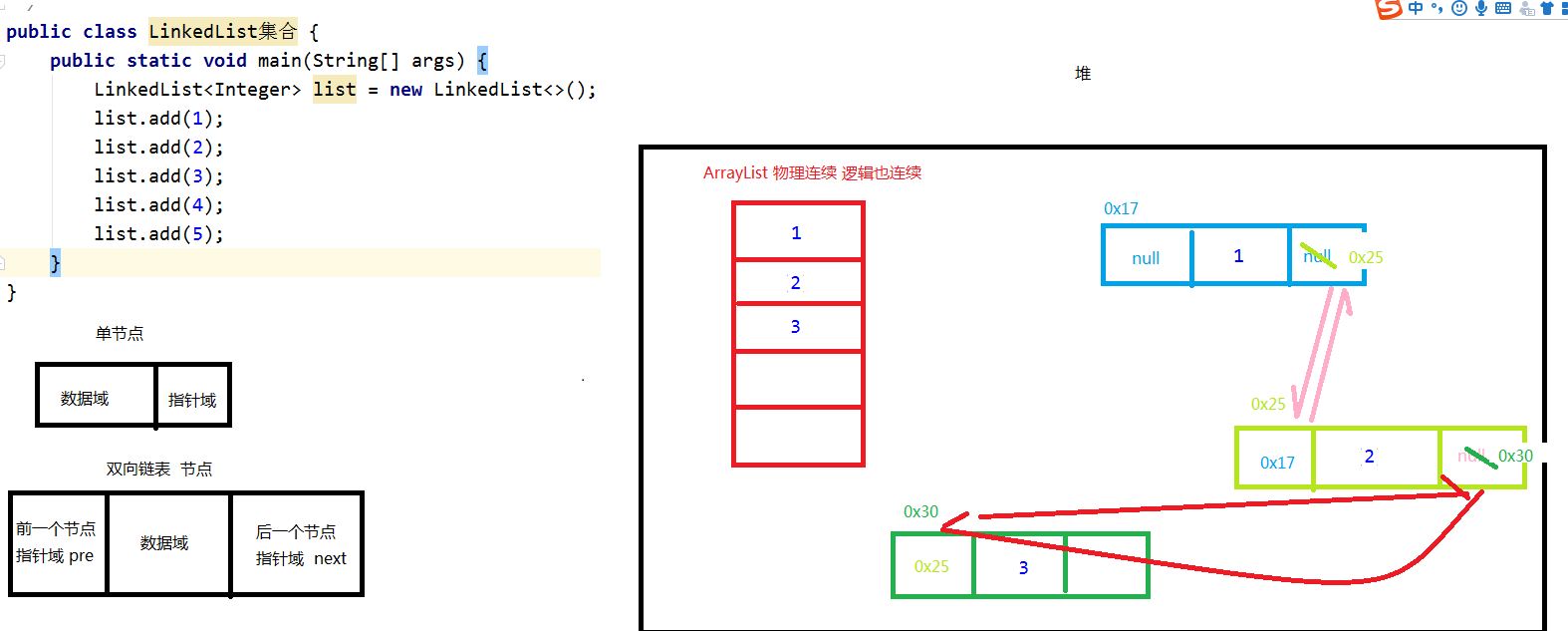
(***)
1.ArrayList与LinkedList的区别?
ArrayList底层是大小可变的数组的实现,查询快 增删慢。线程不安全
LinkedList底层是双向链表的实现,增删快 ,查询慢。线程不安全。
2.LinkedList可以当做堆栈、队列或双端队列。
队列: 先进先出
栈: 先进后出。
原理
1.底层: 双向链表
2.特点: 有序 可重复 可以插入null
代码
package com.demo;
import java.util.LinkedList;
/**
(***) 1.底层: 双向链表
2.特点: 有序 可重复 可以插入null
*/
public class LinkedList集合 {
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
}
}
Vector
用法用Arraylist。该集合是线程安全的,如果需要使用线程安全的集合,可以采用Vector。
单列集合的体系结构和它们之间的区别
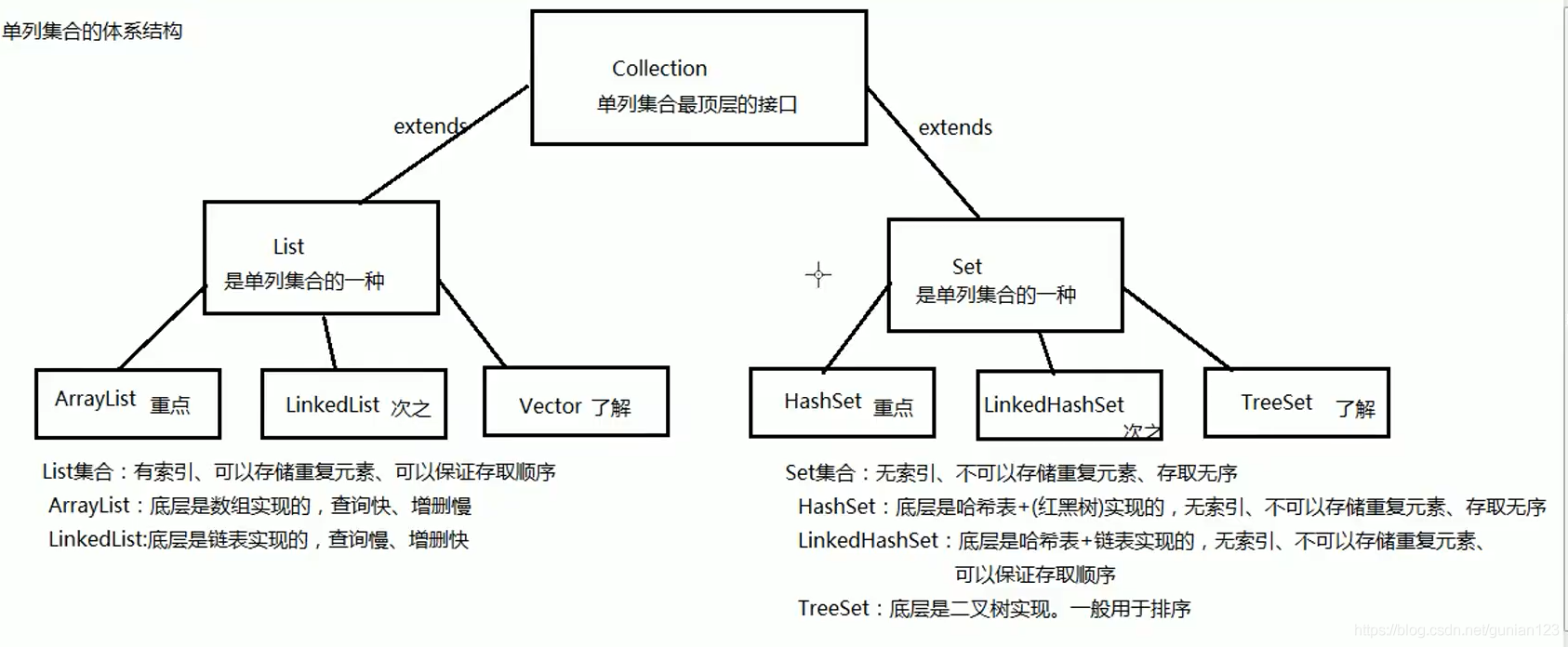
List:其中List的集合查询快,增删慢,原因是因为List的存储的结构是数组结构。
**而List下的_LinkList_**的集合查询慢,增删快。原因是 Linklist的存储结构是链表。在其中有大量操作收尾元素的方法,不过使用其特有的方法时不能使用多态。
Set:在Set中不能有重复元素。没有索引,不能使用普通for循环遍历。是一个无序的集合,储存元素和取出元素的顺序很有可能不一致。底层是一个哈希表结构,查询速度很快。
Set下的_HashSet_:首先要明白哈希值。是系统模拟的地址,而不是真实的地址,不同对象的哈希值不一样,如果对求哈希值的方法进行重写,那么就能使哈希值相同。String下的所有哈希值是一样的。JDK1.8之后,底层是数组加链表/红黑,如果链表的长度超过8位就会转换为红黑树。
HashSet不能存储重复元素的原理: Set集合在调用add方法的时候,add方法会调用元素的hashcode方法和equals方法。如果没有相同的哈希值,就放入集合,如果相同就调用equals方法。返回true就不会存储集合中。
(equals默认比较两个对象地址值,自定义上的类型一定要重写hashcode方法和equals方法)
Set下的_LinkedHashSet_:LinkedHashSet继承了HashSet,比HashSet多了一条链表(记录元素的存储数据),保证元素有序。也不允许重复。
Set集合
概述
Set集合特点: 不重复,只能存储一个null
HashSet
1.特点:无序 不重复,只能存储一个null
2.构造方法: HashSet() 初始容量是16
3.底层: 哈希表 ()
4.如何对自定义类的对象的存储进行去重复: 重写hashCode和equals。
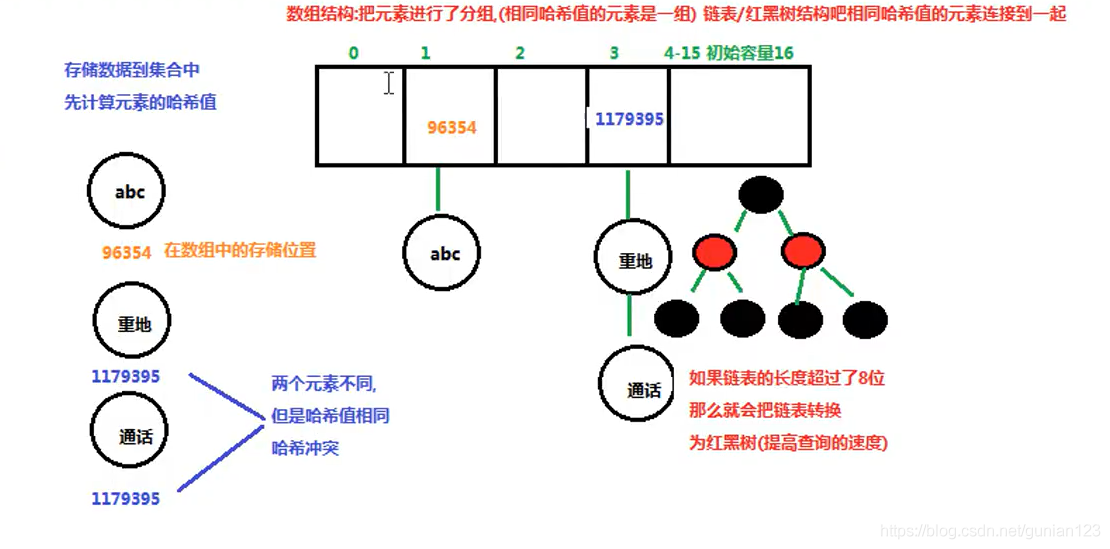
5.HashSet存储原理: ① hashCode() ② equals
① 将存储到集合中的元素,调用该元素的hashCode方法,算出哈希码值,然后根据哈希算法,换 算出在哈希表中的位置,如果该位置没有元素,直接插入。
② 如果该位置有元素,这种现象称为哈希碰撞也叫哈希冲突。发生了这种情况,调用equals方法 进行判断,如果返回值为false,在该索引位置下以链表的形式插入。
③ 如果发生了哈希冲突之后,调用equals方法判断结果为true。此时不插入。
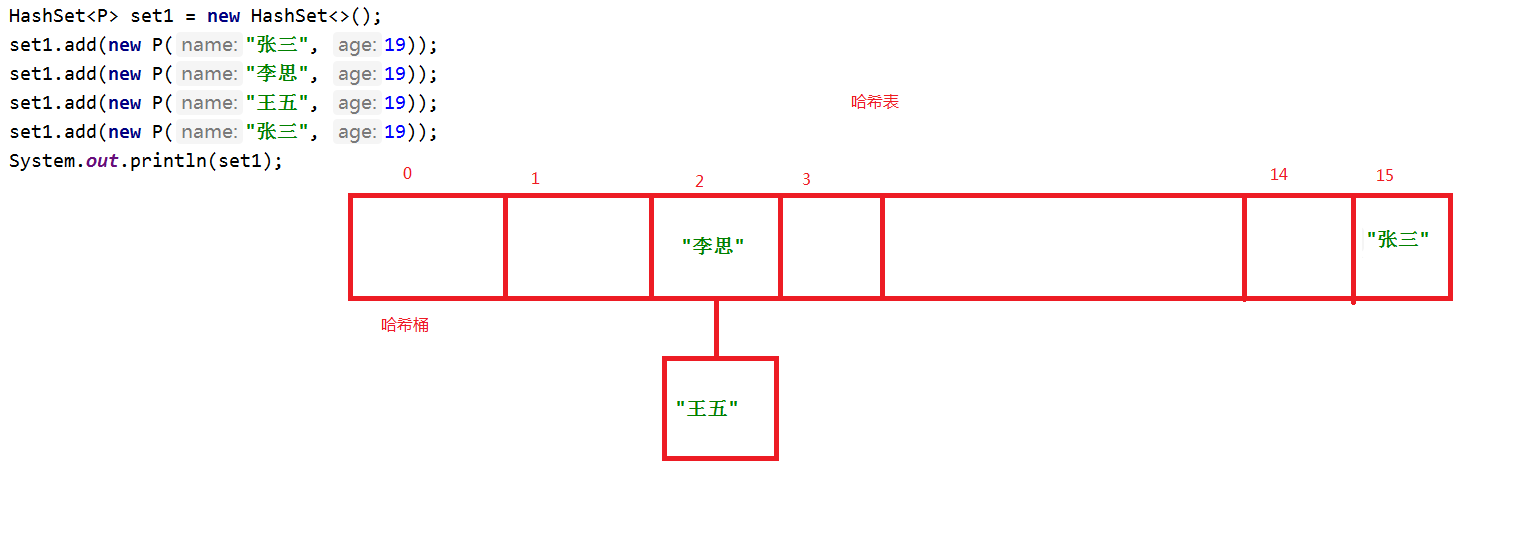
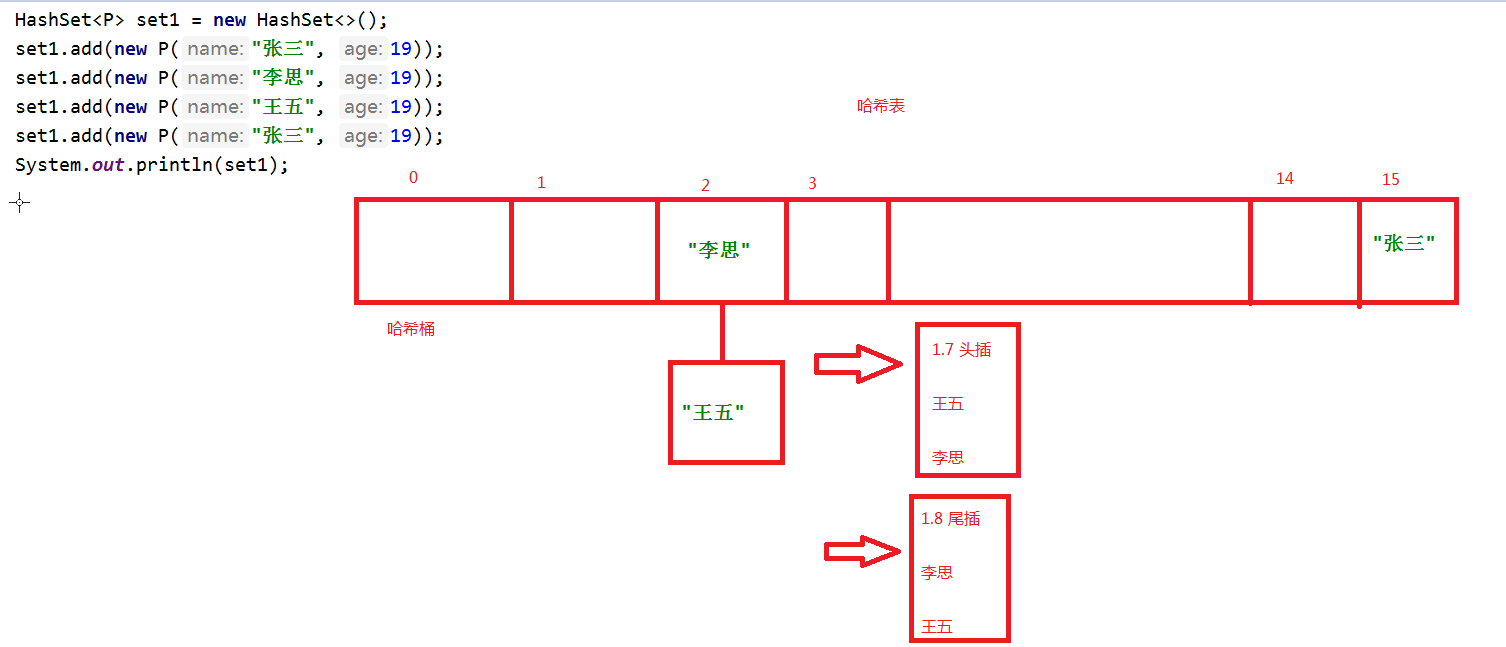
6.HashSet存储细节问题:
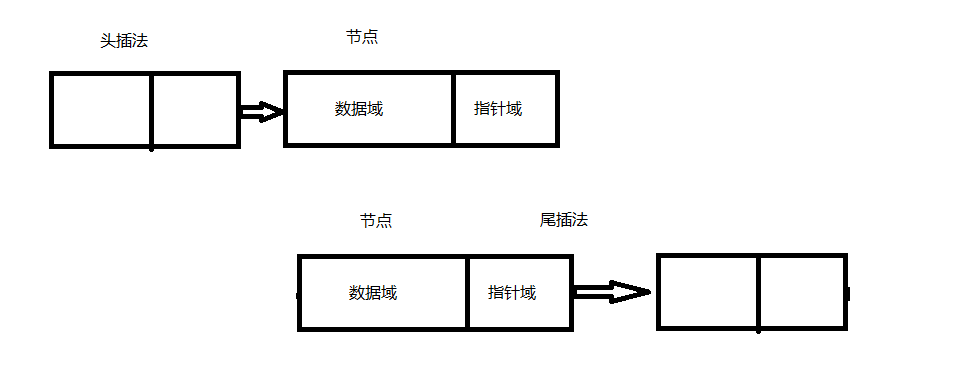
① 发生哈希冲突插入形式:
1》 1.7jdk以前 ,头插法
2》 1.8jdk之后 ,尾插法
2.哈希桶存储元素:
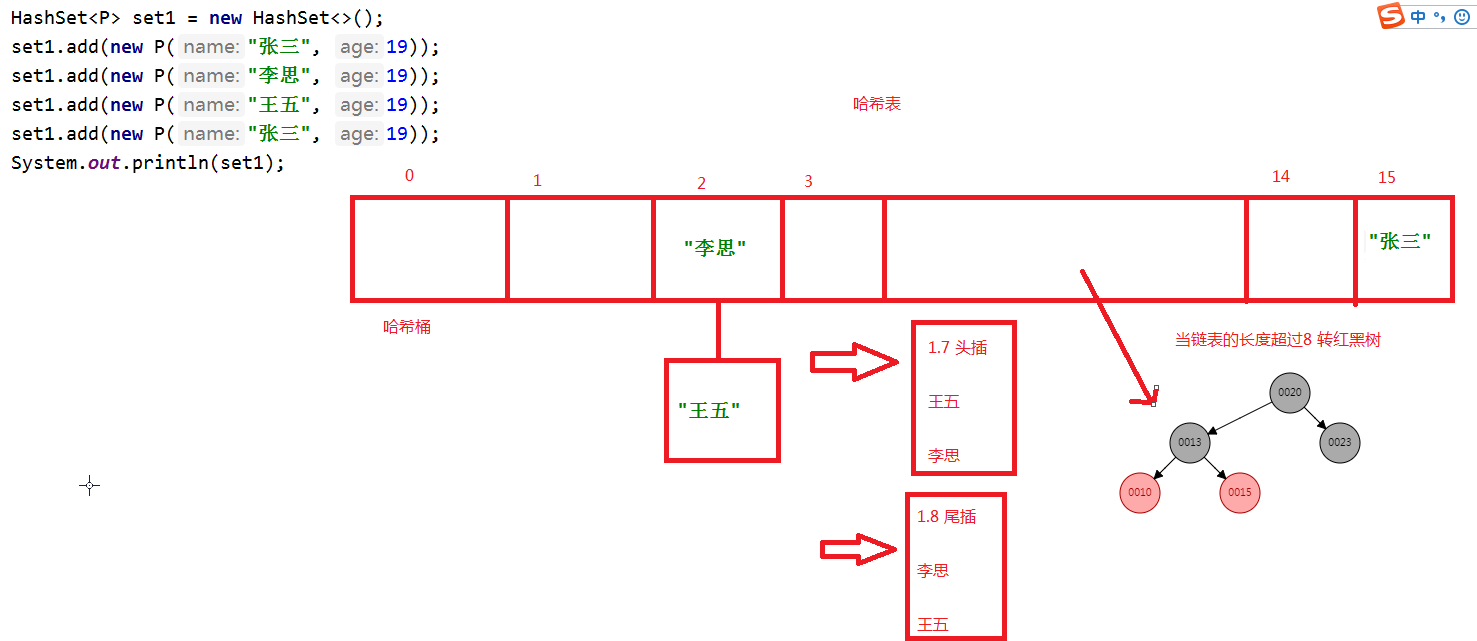
1.7之前 采用链表的形式。
1.8之后 采用链表 + 红黑树的形式
阈值是8 ,当链表长度超过8的时候,从链表转换成红黑树。
阈值小于5,红黑树转链表。
3.加载因子:
当哈希桶容量*加载因子超过这个数值时,就扩容。
注意:
扩容还是转树不是必然的,不是硬性超过阈值为8 就转。需要看扩容和转树哪个性能更好,哪个好转哪个。
红黑树
红黑树(Red Black Tree) 是一种自平衡二叉查找树
二叉树:
二叉查找树:
特点:
一棵空树,或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的结点。
总结:
左小右大,没有相等
TreeSet集合
概述
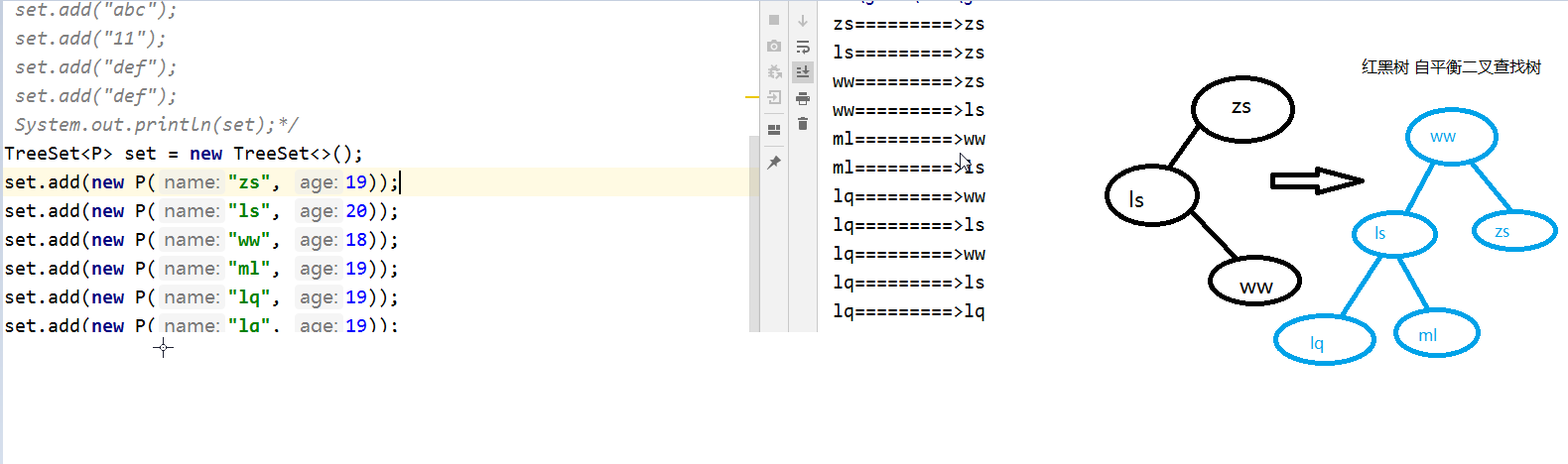
(***)TreeSet底层: 基于红黑树的TreeMap集合。
(***)TreeSet的特点: 无序 不重复 可存储一个null 可排序
1.注意:
① 使用TreeSet()构造方法时,默认会使用元素的自然顺序比较器,如果存储在该集合中的类
没有实现Comparable该接口,
会报ClassCastException类型转换异常。
② TreeSet集合在进行存储时,会自动调用ComparaTo方法进行判断,根据 >0 <0 ==0的结
果进行插入。
如果等于0 不插入。
2.TreeSet利用比较器进行比较的,如果自定义类去重,不需要重写hashCode和equals。
第三方比较器
概述
1.TreeSet(Comparator< ? super E> comparator)
2.Comparator :
第三方比较器 :
compare(T o1, T o2)
相当于 compareTo方法中的:this相当于o1 o 相当于o2.
3.当存在第三方比较器时,根据就近原则,第三方比较器优先有效。
代码
package com.demo;
import java.util.Comparator;
import java.util.TreeSet;
/**
1.TreeSet(Comparator<? super E> comparator)
2.Comparator :第三方比较器 :
compare(T o1, T o2)
相当于 compareTo方法中的:this相当于o1 o 相当于o2.
3.当存在第三方比较器时,根据就近原则,第三方比较器优先有效。
*/
public class 第三方比较器 {
public static void main(String[] args) {
TreeSet<Person> set = new TreeSet<>(new NameComparator());
set.add(new Person("zs", 19));
set.add(new Person("ls", 20));
System.out.println(set);
}
}
class NameComparator implements Comparator<Person>{
@Override
public int compare(Person o1, Person o2) {
return o1.name .compareTo(o2.name);
}
}
class Person implements Comparable<Person>{
String name;
int age ;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Person o) {
return this.age -o.age;
}
}
LinkedHashSet
概念
(***)底层: 哈希表和双向链表组成。
(***)特点: 有序 不重复 可以存储一个null
场景:
购物车 商品历史浏览记录
Map
Map
双列集合:
Map<K,V>
将键映射到值的对象。一个映射不能包含重复的键;键与值是一一对应的关系,键不能重复,但是值可
以重复。
1.Map集合常用方法:
① put(key,value) 将键值对添加到集合 add方法。
注意:
键如果重复,会覆盖原有的值,并且将原有的值返回。
② containsKey(Object key) /containsValue(Object value) 包含
注意:
自定义类的对象需要重写hashCode和equals
(***)③ get(Object key) 通过key获取value
④ Collection
2.Map对象的创建 :
① HashMap() 创建初始容量为16,加载因子0.75
代码
package com.demo;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/**
1.Map集合常用方法:
① put(key,value) 将键值对添加到集合 add方法。
注意:
键如果重复,会覆盖原有的值,并且将原有的值返回。
② containsKey(Object key) /containsValue(Object value) 包含
注意:
自定义类的对象需要重写hashCode和equals
(***)③ get(Object key) 通过key获取value
④ Collection<V> values() 获取值的集合。
2.Map对象的创建 :
① HashMap() 创建初始容量为16,加载因子0.75
*/
public class Map集合的常用方法 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("一", 1);
map.put("二", 2);
map.put("三", 3);
System.out.println(map);
/*Integer it = map.put("三", 5);
System.out.println(it);*/
// ② containsKey(Object key) /containsValue(Object value) 包含
// System.out.println(map.containsKey("二"));
// (***)③ get(Object key) 通过key获取value
// System.out.println(map.get("二"));
// ④ Collection<V> values() 获取值的集合。
Collection<Integer> cl = map.values();
System.out.println(cl);
}
}
Map集合的遍历方式之一
Map集合的遍历:
① keySet()
思路:
Map集合没有迭代器,Map集合需要先转Set集合,然后迭代。
代码
package com.demo;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
/**
Map集合的遍历:
① keySet()
思路:
Map集合没有迭代器,Map集合需要先转Set集合,然后迭代。
*/
public class Map集合的遍历 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("一", 1);
map.put("二", 2);
map.put("三", 3);
Set<String> keys = map.keySet();
//遍历
Iterator<String> it = keys.iterator();
while (it.hasNext()){
String key = it.next();
System.out.println(key +"==>" + map.get(key));
}
}
}
Map.Entry
Map.Entry
映射项(键-值对)。
1.Map集合的遍历方式二:
Map.Entry Map中的子接口。
2.常用方法:
① getKey()获取键
② getValue() 获取值
3.Map的常用方法:
entrySet() 获取Map.Entry的Set集合
代码
package com.demo;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
//import java.util.Map.Entry; //直接写Entry 可以在该位置导包
/**
1.Map集合的遍历方式二:
Map.Entry Map中的子接口。
2.常用方法:
① getKey()获取键
② getValue() 获取值
3.Map的常用方法:
entrySet() 获取Map.Entry的Set集合。
*/
public class Map的遍历方式二 {
public static void main(String[] args) {
HashMap<String,Integer> map = new HashMap<>();
map.put("二", 2);
map.put("三", 3);
map.put("一", 1);
Set<Map.Entry<String,Integer>> entry = map.entrySet();
//遍历
/*Iterator<Map.Entry<String,Integer>> it = entry.iterator();
while(it.hasNext()){
Map.Entry<String,Integer> en = it.next();
System.out.println(en.getKey() + "====="+ en.getValue());
}*/
for (Iterator<Map.Entry<String,Integer>> it = entry.iterator(); it.hasNext();){
Map.Entry<String, Integer> value = it.next();
System.out.println(value.getKey() + "==="+ value.getValue());
}
}
}
HashMap
概述
底层:
基于哈希表的实现。
特点:
键值对的映射,一个键对应一个值,键是不重复的,键无序
HashMap 细节问题:
自定义类做键: 需要重写hashCode和equals方法。
代码
package com.demo;
import java.util.HashMap;
import java.util.Map;
/**
1.HashMap 细节问题:
自定义类做键: 需要重写hashCode和equals方法。
*/
public class HashMap细节问题 {
public static void main(String[] args) {
/*HashMap<String ,Person> map = new HashMap<>();
map.put("张三",new Person("张三", 19));
map.put("张三1",new Person("张三1", 19));
map.put("张三2",new Person("张三2", 19));
map.put("张三2",new Person("张三2", 20));
System.out.println(map);*/
HashMap<Person,String> map = new HashMap<>();
map.put(new Person("zs", 19), "zs");
map.put(new Person("zs1", 19), "zs1");
map.put(new Person("zs2", 19), "zs2");
map.put(new Person("zs3", 19), "zs3");
map.put(new Person("zs3", 19), "zs5");
System.out.println(map);
}
}
class Person{
String name;
int age ;
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (age != person.age) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
}
TreeMap
概述
底层:基于红黑树(Red-Black tree)的 NavigableMap 实现
特点:
键值对的映射,一个键对应一个值,键是不重复的,键无序 键可排序
TreeMap 细节问题:
自定义类做键: 需要在类或者构造方法中使用比较器。
代码
package com.demo;
import java.util.Comparator;
import java.util.TreeMap;
/**
*/
public class TreeMap细节问题 {
public static void main(String[] args) {
/*TreeMap<String,Student> map = new TreeMap<>();
map.put("张三", new Student("张三", 19));
map.put("张三", new Student("张三1", 19));
System.out.println(map);*/
TreeMap<Student ,String> map = new TreeMap<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o1.name.compareTo(o2.name);
}
});
map.put(new Student("zs", 19), "zs");
map.put(new Student("zs", 19), "zs1");
System.out.println(map);
}
}
class Student {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public Student() {
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Collections
概述
集合工具类
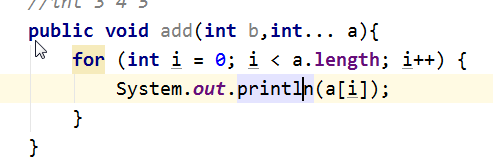
可变参数

格式:
数据类型… 变量的名称
调用可变参数的方法时,可以传递0-任意个参数,但是定义可变参数对应的方法时,要求可变参数定
义在最后。
实质: 数组
常用方法
1.常用方法:
① addAll(Collection<? super T> c, T… elements) 添加元素到集合
② fill(List<? super T> list, T obj) 替换
③ max/min (Collection<? extends T> coll, Comparator<? super T> comp) 求最大小值
④ sort(List
排序默认没有第二个参数表示按元素的自然顺序进行排序,有按第三方比较器
⑤ shuffle(List list) 随机置换
代码
package com.demo;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
/**
1.常用方法:
① addAll(Collection<? super T> c, T... elements) 添加元素到集合
② fill(List<? super T> list, T obj) 替换
③ max/min (Collection<? extends T> coll, Comparator<? super T> comp) 求最大小值
④ sort(List<T> list, Comparator<? super T> c)
排序默认没有第二个参数表示按元素的自然顺序进行排序,有按第三方比较器
⑤ shuffle(List<?> list) 随机置换
*/
public class 集合工具类 {
public static void main(String[] args) {
// A a = new A();
// a.add();
ArrayList<String> list = new ArrayList<>();
// Collections.addAll(list,"abc","bcd","def");
/* System.out.println(list);*/
// ② fill(List< ? super T> list, T obj) 替换
/* Collections.fill(list,"kkk");
System.out.println(list);*/
// ③ max/min (Collection<? extends T> coll, Comparator<? super T> comp) 求最大小值,如果没有第二个参数表示按照元素的自然顺序进行排序。
/* String max = Collections.max(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.compareTo(o1);
}
});
System.out.println(max);*/
// ⑤ shuffle(List<?> list) 随机置换
Collections.addAll(list,"1","2","3","4","5","6");
Collections.shuffle(list);
System.out.println(list);
}
}
class A {
//int 3 4 5
public void add(int b,int... a){
for (int i = 0; i < a.length; i++) {
System.out.println(a[i]);
}
}
}
集合总结
单列集合
-
Collection:
-
List:有序 可重复 可插入多个null
-
ArrayList:底层: 大小可变的数组的实现。
特点: 有序 可重复 可插入多个null 查询快
增删慢 线程不安全
-
LinkedList:底层: 双向链表
特点:有序 可重复 可插入多个null 查询慢
增删快 线程不安全
-
Vector:用法同ArrayList 线程安全
-
-
Set:无序 不重复 只能插入一个null
-
HashSet:底层: 哈希表–》HashMap
特点:无序 不重复 只能插入一个null 线程不安全
自定义类对象去重:重写hashCode和equals方法
存储原理:
1.8jdk结构改进。
-
LinkedHashSet:底层: 哈希表+双向链表
特点:有序 不重复 只能插入一个null 线程不安全
-
TreeSet:底层: 基于红黑树的TreeMap
特点:可排序 无序 不重复 只能插入一个null 线程不安全
比较器:① 元素的自然顺序比较器: Comparable
② 第三方比较器:Comparator
-
-
通用方法
1.add()
2.List–>get(index)
3.集合的遍历: 五种 ,Set :迭代器 增强for 转数组r