1. 理解
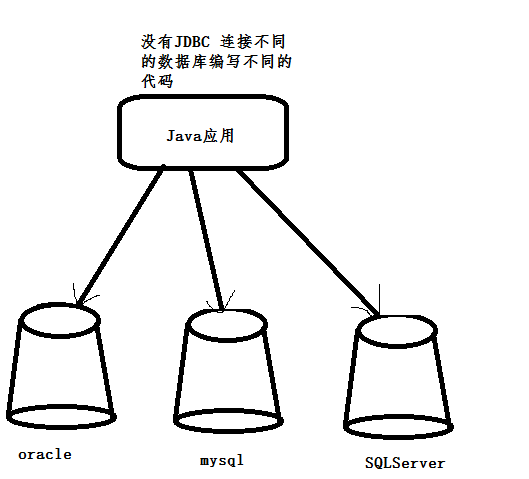
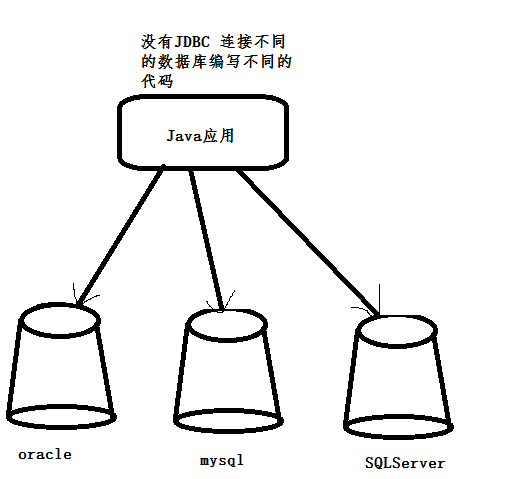
Java Databases Connectivity 是一种独立于数据库系统、通用SQL数据库存取和操作的一组接口(一组API)
2. 作用
1. JDBC提供了一组API 开发者只需要针对一组API开发即可,为开发者屏蔽了一些问题
2. JDBC为连接不同的数据库提供了统一的路径
3. 根据不同的数据库厂商提供不同的驱动 提高了维护性
3. 使用
包:java.sql.* javax.sql.*
一个类(DriverManager) 三个接口(Connection、Statement、ResultSet)
使用步骤:
1. 加载驱动
Class.forName("com.mysql.jdbc.Driver")
2. 获取连接
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/库名", "root", "密码")
3. 创建命令对象
Statement st = conn.createStatement();
4. 编写SQL
String sql = "";
5. 执行命令 返回结果
ResultSet rs = st.executeQuery(sql); // 执行查询
int row = st.executeUpdate(sql); // 执行增删改
6. 处理结果
7. 关闭资源
rs.close();
st.close();
conn.close();
JDBC优化
1. 优化1:SQL注入
1. SQL注入问题:
SQL中出现了特殊的字符 导致SQL语句发生变化 引发结果不正确
2. 解决:
使用PreparedStatement预编译命令接口 替代 Statement接口
3. 原理:
·对SQL语句先编译 检查传递的内容 如果出现了特殊字符 给转义
·SQL语句中使用? 作为占位符 只对?的内容 检查转义
4. PreparedStatement是Statement的子接口
· 避免SQL中拼接变量 引发问题
· 复用SQL语句
2. 优化2:连接对象
1. 连接池的必要性
· 连接资源没有得到复用,导致连接资源创建很多次 占用系统资源
· 连接资源创建和关闭都需要时间 导致程序效率降低
· 过多的连接请求导致 数据库系统宕机
· 连接资源不关闭 造成内存泄漏
2. 连接池的好处
· 提高连接资源的复用性
· 提高系统的执行效率 连接资源统一由连接池管理
· 合理的分配 连接资源
· 减少数据库宕机的可能性
3. 开源的连接池
· DBCP连接池
· C3P0连接池
· Druid连接池
4. 连接池的使用
C3P0使用:
1. 下载导包 c3p0-0.9.5.2.bin.zip
2. 引入jar c3p0-0.9.5.2.jar mchange-commons-java-0.2.11.jar
3. 编写代码
方式1:代码配置
方式2:配置文件方式 (推荐使用)
① 在src下创建 c3p0.properties
② 在c3p0.properties 配置数据源
③ 创建连接池对象
// 1. 创建连接池对象
ComboPooledDataSource cpds = new ComboPooledDataSource();
// 2. 使用
connection = cpds.getConnection();
Druid使用
1. 下载导包 druid-1.1.10.zip
2. 引入 jar druid-1.1.10.jar
3. 编码
① 在src下创建 druid.properties
② 在druid.properties 配置数据源
③ 使用
// 1. 读取配置文件
Properties properties = new Properties();
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("druid.properties");
properties.load(is);
//2. 创建连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
// 3. 使用
connection = dataSource.getConnection();

3. 优化3:封装连接池工具类
封装连接池工具类 连接池只被创建一次
1. 将连接池的创建 封装到静态代码块中
2. 获取连接池对象的方法 静态方法
4. 优化4:连接对象线程安全
JDK1.2 ThreadLocal类
原理:
将有可能引发线程安全的对象,绑定在ThreadLocal中。将该对象复制一份作为本地线程的局部变量,该对象只能当前线程使用。因此源对象不会发生任何变化,所以解决了线程安全问题。
使用:
① 将线程安全问题的对象绑定到ThreadLocal
private static ThreadLocal<Connection> tl = new ThreadLocal<>();
② 获取绑定的连接对象
Connection conn = tl.get();
③ 绑定连接对象到
tl.set(conn);
④ 解绑
tl.remove()
package com.ujiuye.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.io.InputStream;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
/*
* 封装连接池工具类 连接池只被创建一次
* 1. 将连接池的创建 封装到静态代码块中
* 2. 获取连接池对象的方法 静态方法
* 3. 释放连接对象 静态方法
*
*
*
* */
public class JDBCUtils {
// 1. 解决线程安全问题 实例化ThreadLocal
private static ThreadLocal<Connection> tl = new ThreadLocal<>();
static DataSource dataSource;
static {
try {
// 1. 读取配置文件
Properties properties = new Properties();
InputStream is = Thread.currentThread().getContextClassLoader()
.getResourceAsStream("druid.properties");
properties.load(is);
// 2. 创建连接池对象
dataSource = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
// 获取连接
public static Connection getConnection() throws SQLException {
// 1. 先从threadlocal中获取连接对象
Connection connection = tl.get();
// 2. 判断是否 已经绑定
if(connection==null){
// 3. 从池子中获取连接
connection = dataSource.getConnection();
// 4. 将该连接绑定到ThreadLocal上
tl.set(connection);
}
return connection;
}
// 1. 封装释放的方法
public static void release(){
// 1. 获取绑定上的连接
Connection connection = tl.get();
if(connection!=null){
// 2. 解绑
tl.remove();
// 3. 放回池子
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
5. 优化5:dbutils工具类
理解:
dbutils工具类 是 apacha提供的将操作数据库的步骤 和 返回结果为了封装
使用:
1. 下载导包 commons-dbutils-1.7-bin.zip
2. 导入jar commons-dbutils-1.7.jar
3. 使用
① 创建核心对象
QueryRunner qr = new QueryRunner();
② 调用方法
// 执行增删改
int row = qr.update(conn, sql, sql中参数);
// 执行查询
// BeanHandler 映射一个对象
// BeanListHandler 映射多个对象 返回list
// ScaleHandler 返回聚合结果
qr.query(conn,sql, ResultSetHandler,Object...obj)
6. 优化6:封装通用DAO
想法:
每一个表都有dbutils 增删改查的功能,通过面向对象的继承思想。将增删改查的封装到父类中,只需要创建子类继承父类 子类具有了增删改查的功能。
封装:
package com.ujiuye.dao;
import com.ujiuye.utils.JDBCUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.dbutils.handlers.ScalarHandler;
import java.sql.SQLException;
import java.util.List;
/**
* 封装增删改查的通用类
* 1. 封装增删改功能
* 2. 单查功能
* 3. 多查功能
* 4. 查个数功能
*/
public class BasicDao<T> {
QueryRunner qr;
{
qr = new QueryRunner();
}
// 1. 增删改
public int update(String sql, Object...params){
try {
return qr.update(JDBCUtils.getConnection(), sql, params);
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
JDBCUtils.release();
}
}
// 2. 单查
public T querySingle(String sql, Class<T> clazz, Object...params){
try {
return qr.query(JDBCUtils.getConnection(), sql, new BeanHandler<>(clazz), params);
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
JDBCUtils.release();
}
}
// 3. 多查
public List<T> queryMore(String sql, Class<T> clazz, Object...params){
try {
return qr.query(JDBCUtils.getConnection(), sql, new BeanListHandler<>(clazz), params);
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
JDBCUtils.release();
}
}
// 4. 查个数
public Object scale(String sql, Object...params){
try {
return qr.query(JDBCUtils.getConnection(), sql, new ScalarHandler<>(), params);
} catch (SQLException e) {
throw new RuntimeException(e);
} finally {
JDBCUtils.release();
}
}
}
总结
JDBC最终使用步骤:
1. 导入第三方jar
mysql-connector-java-5.1.44-bin.jar
druid-1.1.10.jar
commons-dbutils-1.7.jar
2. 导入数据源 配置文件 引入src目录
druid.properties
3. 导入连接池工具类JDBCUtils
4. 导入通用DAO
5. 创建类继承DAO
一、补充
####1. junit单元测试
* 测试:白盒测试(代码测试) 黑盒测试(功能性测试)
* junit单元测试用法
* 1. 自定类
* 2. 定义测试方法 (可以多个)
* public修饰 无返回值 无参 @Test注解
* 3. 常见注解
*
* @BeforeClass 测试方法执行之前执行 只执行一次
* @Before 每个测试方法执行之前 都会执行一次
@Test 标注当前方法为测试方法
@After 每个测试方法执行之后 都会执行该方法
@AfterClass 测试方法执行完毕之后执行 只执行一次
2. 事务
1. 开启事务
conn.setAutoCommit(false);
2. 成功 提交事务
conn.commit();
3. 失败 回滚事务
conn.rollBack()
3. 批处理
1. 添加批处理
ps.addBatch();
2. 执行批处理
ps.executeBatch();
3. 清除批处理
ps.clearBatch