第2章
服务网关、Sentinel、Sleuth
优就业.JAVA教研室
学习目标
- 了解 SpringCloudGateWay
- 理解 SpringCloudGateWay路由配置
- 理解SpringCloudGateWay全局过滤
- 理解Sentinel介绍
- 掌握Sentinel快速开始
- 掌握Sentinel整合Feign
- 掌握Sentinel流量控制
- 掌握Sentinel熔断降级
- 掌握Sentinel规则持久化
- 掌握Sleth介绍
- 掌握Sleth基本使用
1. 服务网关Gateway
API 网关出现的原因是微服务架构的出现,不同的微服务一般会有不同的网络地址,而外部客户端可能需要调用多个服务的接口才能完成一个业务需求,如果让客户端直接与各个微服务通信,会有以下的问题:
-
破坏了服务无状态特点。
为了保证对外服务的安全性,我们需要实现对服务访问的权限控制,而开放服务的权限控制机制将会贯穿并污染整个开放服务的业务逻辑,这会带来的最直接问题是,破坏了服务集群中REST API无状态的特点。
从具体开发和测试的角度来说,在工作中除了要考虑实际的业务逻辑之外,还需要额外考虑对接口访问的控制处理。 -
无法直接复用既有接口。
当我们需要对一个即有的集群内访问接口,实现外部服务访问时,我们不得不通过在原有接口上增加校验逻辑,或增加一个代理调用来实现权限控制,无法直接复用原有的接口。
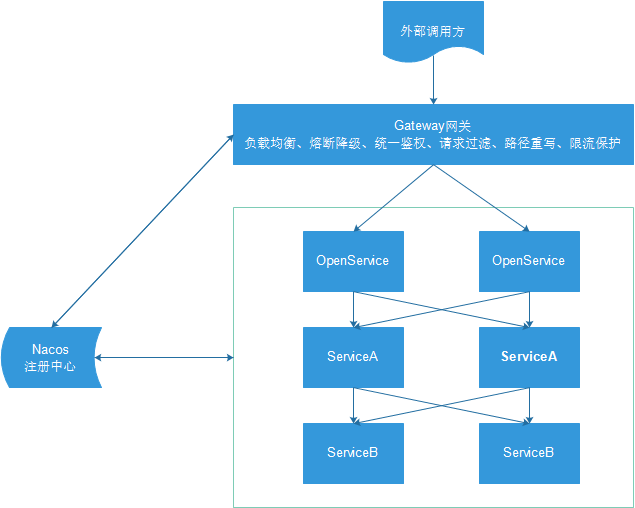
以上这些问题可以借助 API 网关解决。API 网关是介于客户端和服务器端之间的中间层,所有的外部请求都会先经过 API 网关这一层。也就是说,API 的实现方面更多的考虑业务逻辑,而安全、性能、监控可以交由 API 网关来做,这样既提高业务灵活性又不缺安全性,典型的架构图如图所示:
1.1. 快速开始
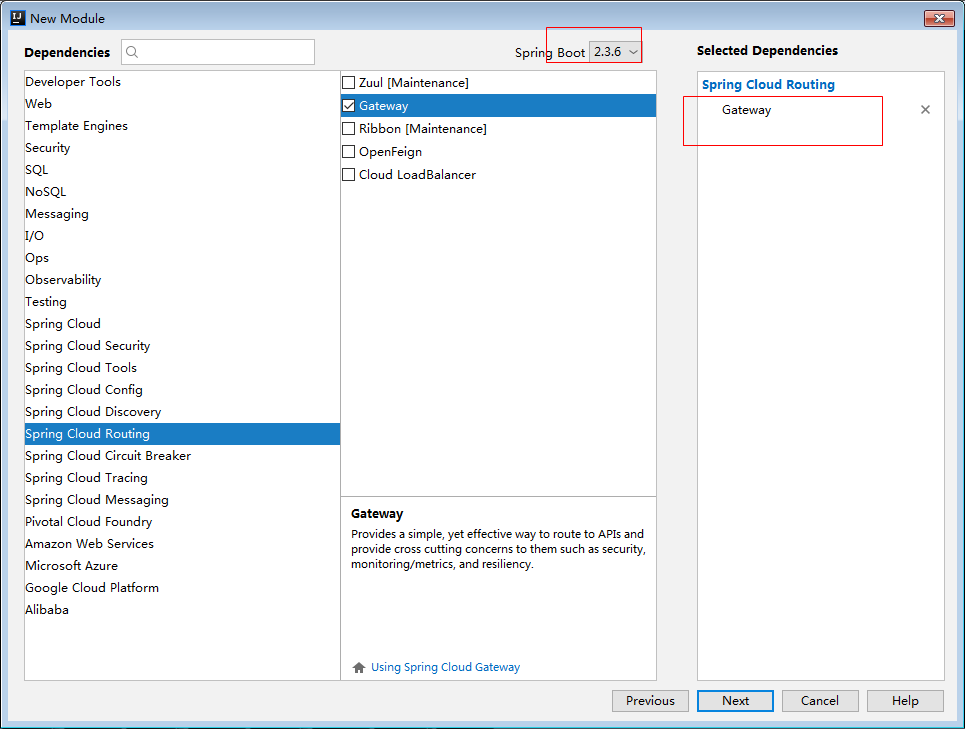
创建网关module:
完成后:
1.1.1. 引入依赖
已引入,如下。pom.xml中的依赖:
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR2</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
1.1.2. 编写路由规则
为了演示路由到不同服务,这里把消费者和生产者都配置在网关中
application.yml
server:
port: 18090
spring:
cloud:
gateway:
routes:
- id: nacos-consumer
uri: http://127.0.0.1:18080
predicates:
- Path=/hi
- id: nacos-provider
uri: http://127.0.0.1:18070
predicates:
- Path=/hello
1.1.3. 启动测试
通过网关路径访问消费者或者生产者。

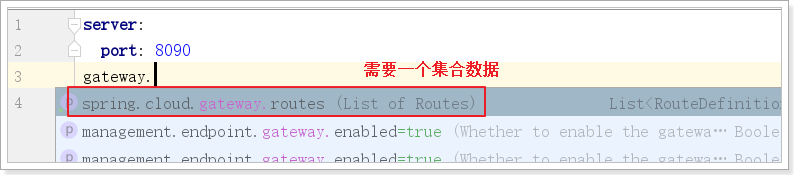
1.2. 路由规则详解
基本概念:
- Route:路由网关的基本构建块。它由ID,目的URI,断言(Predicate)集合和过滤器(filter)集合组成。如果断言聚合为真,则匹配该路由。
- Predicate:这是一个 Java 8函数式断言。允许开发人员匹配来自HTTP请求的任何内容,例如请求头或参数。
- 过滤器:可以在发送下游请求之前或之后修改请求和响应。
路由根据断言进行匹配,匹配成功就会转发请求给URI,在转发请求之前或者之后可以添加过滤器。
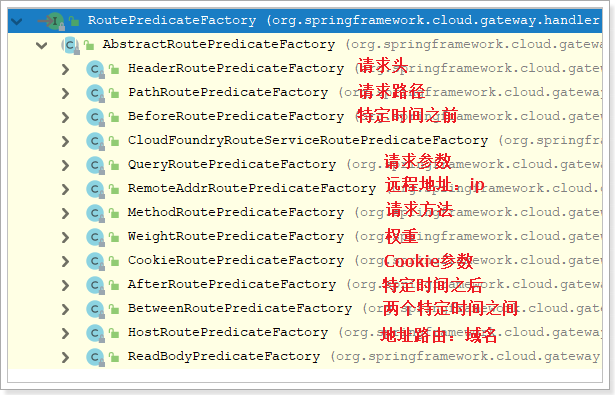
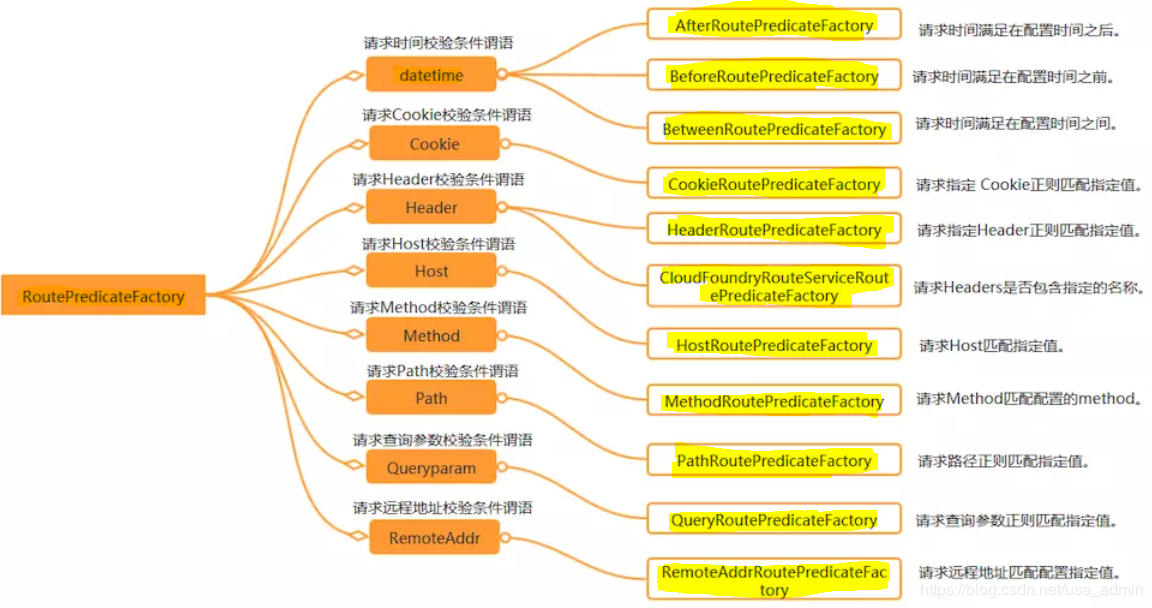
1.2.1. 断言工厂
Spring Cloud Gateway包含许多内置的Route Predicate工厂。所有这些断言都匹配HTTP请求的不同属性。多路由断言工厂通过and组合。
官方提供的路由工厂:
这些断言工厂的配置方式,参照官方文档:https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.1.0.RELEASE/single/spring-cloud-gateway.html
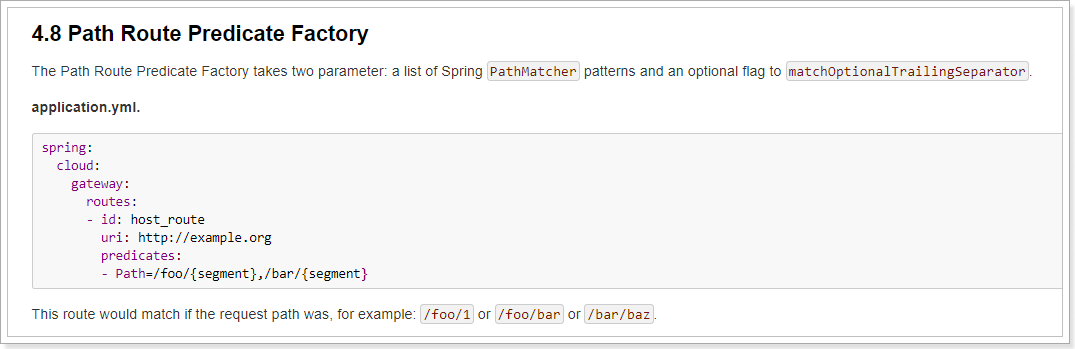
这里重点掌握请求路径路由断言的配置方式:
spring:
cloud:
gateway:
routes:
- id: host_route
uri: http://example.org
predicates:
- Path=/foo/{segment},/bar/{segment}
这个路由匹配以/foo或者/bar开头的路径,转发到http:example.org。例如 /foo/1 or /foo/bar or /bar/baz.
/foo/1 ——>转发地址 http://example.org/foo/1
/foo/bar—–>转发地址 http://example.org/foo/bar
1.2.2. 过滤器工厂
路由过滤器允许以某种方式修改传入的HTTP请求或传出的HTTP响应。路径过滤器的范围限定为特定路由。Spring Cloud Gateway包含许多内置的GatewayFilter工厂。
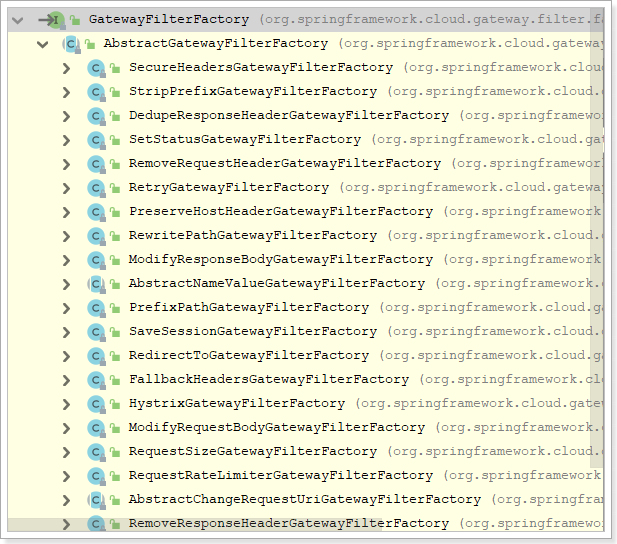
这些过滤器工厂的配置方式,同样参照官方文档:https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.1.0.RELEASE/single/spring-cloud-gateway.html

过滤器 有 20 多个 实现类,根据过滤器工厂的用途来划分,可以分为以下几种:Header、Parameter、Path、Body、Status、Session、Redirect、Retry、RateLimiter和Hystrix
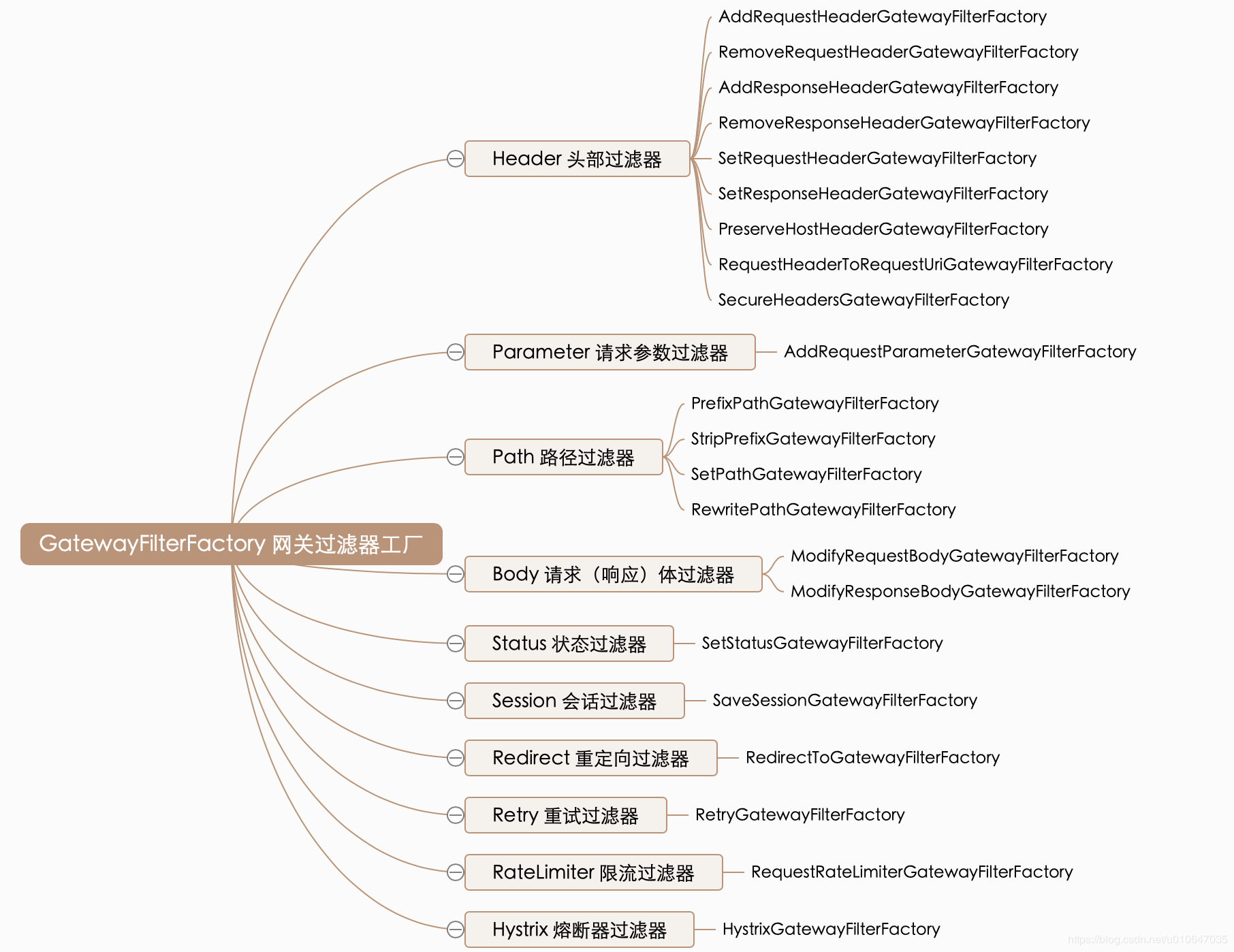
这里重点掌握PrefixPath GatewayFilter Factory
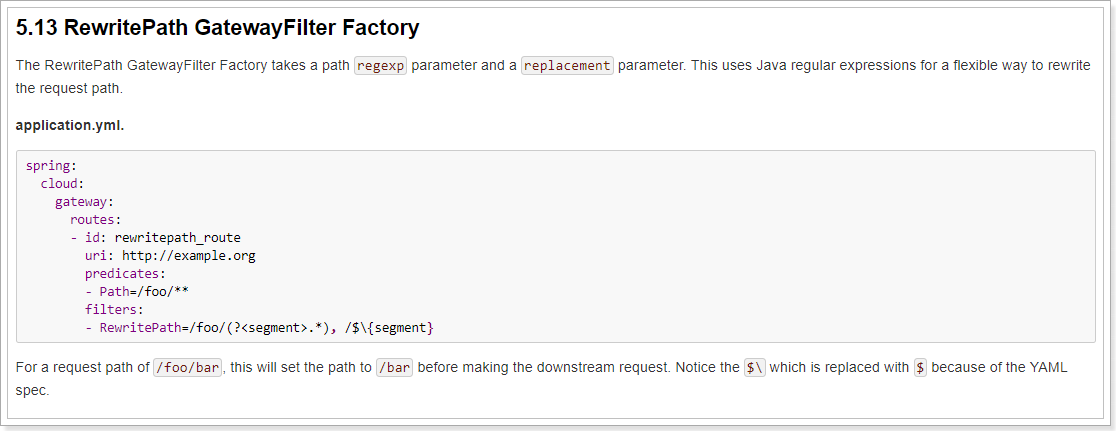
上面的配置中,所有的`/foo/**`开始的路径都会命中配置的router,并执行过滤器的逻辑,在本案例中配置了RewritePath过滤器工厂,此工厂将`/foo/(?.*)`重写为{segment},然后转发到http://example.org。比如在网页上请求localhost:8090/foo/forezp,此时会将请求转发到http://example.org/forezp的页面
(?<segment>/?.*):匹配 /任意字符,此处/出现0次或1次。将匹配到的结果捕获到名称为segment的组中
$\{segment}:将 segment所捕获到的文本置换到此处,注意,\的出现是由于避免yaml认为这是一个变量,在gateway进行解析时,会被替换为${segment}
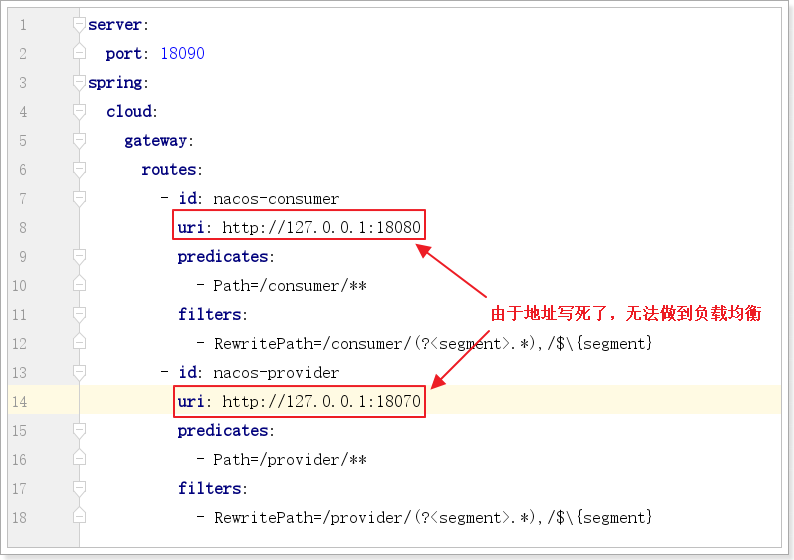
在开发中由于所有微服务的访问都要经过网关,为了区分不同的微服务,通常会在路径前加上一个标识,例如:访问服务提供方:`http://localhost:18090/provider/hello` ;访问服务消费方:`http://localhost:18090/consumer/hi` 如果不重写地址,直接转发的话,转发后的路径为:`http://localhost:18070/provider/hello`和`http://localhost:18080/consumer/hi`明显多了一个provider或者consumer,导致转发失败。
这时,我们就用上了路径重写,配置如下:
server:
port: 18090
spring:
cloud:
gateway:
routes:
- id: nacos-consumer
uri: http://127.0.0.1:18080
predicates:
- Path=/consumer/**
filters:
- RewritePath=/consumer/(?<segment>.*),/$\{segment}
- id: nacos-provider
uri: http://127.0.0.1:18070
predicates:
- Path=/provider/**
filters:
- RewritePath=/provider/(?<segment>.*),/$\{segment}
# - StripPrefix=1
注意:Path=/consumer/**及Path=/provider/**的变化
RewritePath可以实现原来的zuul的StripPrefix的效果,而且功能更强大!
测试:

1.3. 面向服务的路由
如果要做到负载均衡,则必须把网关工程注册到nacos注册中心,然后通过服务名访问。
1.3.1. 把网关服务注册到nacos
-
引入nacos的相关依赖:
<dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- SpringCloud的依赖 --> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Hoxton.SR2</version> <type>pom</type> <scope>import</scope> </dependency> <!-- 在依赖管理中加入springCloud-alibaba组件的依赖 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2.2.0.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> -
配置nacos服务地址及服务名:
application.yml中的配置:
server: port: 18090 spring: application: name: gateway cloud: nacos: discovery: server-addr: 127.0.0.1:8848 gateway: routes: - id: nacos-consumer uri: http://127.0.0.1:18080 predicates: - Path=/consumer/** filters: - RewritePath=/consumer/(?<segment>.*),/$\{segment} - id: nacos-provider uri: http://127.0.0.1:18070 predicates: - Path=/provider/** filters: - RewritePath=/provider/(?<segment>.*),/$\{segment} -
把网关注入到nacos
@SpringBootApplication @EnableDiscoveryClient public class GatewayDemoApplication { public static void main(String[] args) { SpringApplication.run(GatewayDemoApplication.class, args); } }
1.3.2. 修改配置,通过服务名路由
server:
port: 18090
spring:
application:
name: gateway
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848
gateway:
routes:
- id: nacos-consumer
uri: lb://nacos-consumer
predicates:
- Path=/consumer/**
filters:
- RewritePath=/consumer/(?<segment>.*),/$\{segment}
- id: nacos-provider
uri: lb://nacos-provider
predicates:
- Path=/provider/**
filters:
- RewritePath=/provider/(?<segment>.*),/$\{segment}
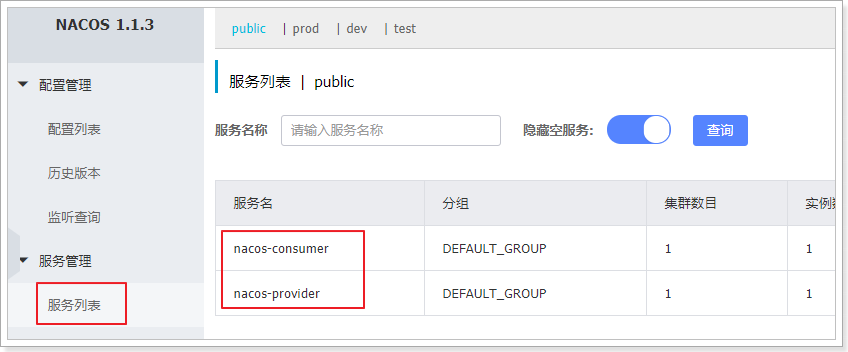
语法:lb://服务名
lb:LoadBalance,代表负载均衡的方式
服务名取决于nacos的服务列表中的服务名
1.4. 路由的java代码配置方式(了解)
参见官方文档:
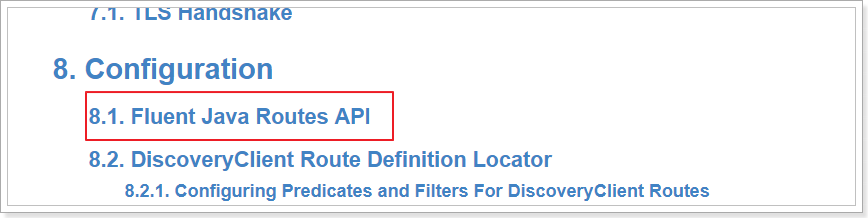
代码如下:
@Configuration
public class RouteLocatorConfig {
@Bean
public RouteLocator customRouteLocator(RouteLocatorBuilder builder){
return builder.routes()
.route(r -> r.path("/api/hello/**")
.filters(f -> f.stripPrefix(1))
.uri("lb://nacos-provider"))
.route(r -> r.path("/ujiuye/hello/**")
.filters(f -> f.rewritePath("/ujiuye/(?<segment>.*)", "/${segment}"))
.uri("lb://nacos-provider"))
.build();
}
}
1.5. 网关全局过滤(了解)
全局过滤器作用于所有的路由,不需要单独配置,我们可以用它来实现很多统一化处理的业务需求,比如权限认证,IP 访问限制等等。
1.5.1 过滤器生命周期
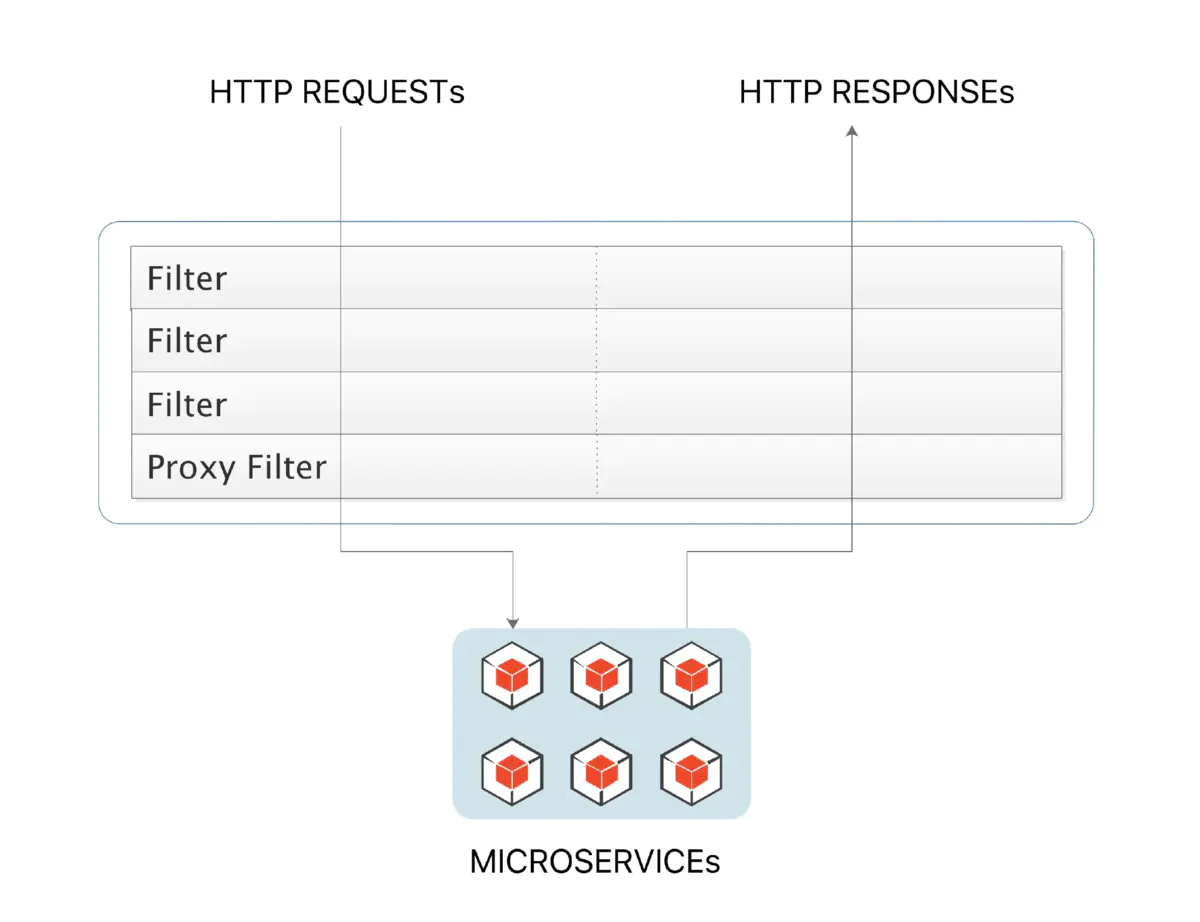
1.5.2 创建全局过滤器
实现 GlobalFilter, Ordered 接口并在类上增加 @Component 注解就可以使用过滤功能了,非常简单方便
package com.offcn.filter;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.collect.Maps;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.util.Map;
@Component
public class AuthFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
String token = exchange.getRequest().getQueryParams().getFirst("token");
if (token == null || token.isEmpty()) {
ServerHttpResponse response = exchange.getResponse();
// 封装错误信息
Map<String, Object> responseData = Maps.newHashMap();
responseData.put("code", 401);
responseData.put("message", "非法请求");
responseData.put("cause", "Token is empty");
try {
// 将信息转换为 JSON
ObjectMapper objectMapper = new ObjectMapper();
byte[] data = objectMapper.writeValueAsBytes(responseData);
// 输出错误信息到页面
DataBuffer buffer = response.bufferFactory().wrap(data);
response.setStatusCode(HttpStatus.UNAUTHORIZED);
response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");
return response.writeWith(Mono.just(buffer));
} catch (JsonProcessingException e) {
e.printStackTrace();
}
}
return chain.filter(exchange);
}
@Override
public int getOrder() {
return 1;
}
}
1.5.3 测试全局过滤器
测试访问地址:http://localhost:18090/consumer/hi
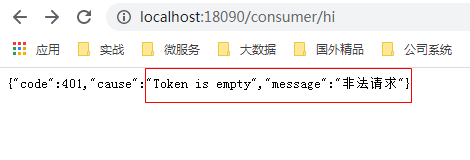
增加token测试访问地址:http://localhost:18090/consumer/hi?token=aaaa

2. Sentinel
分布式系统的流量防卫兵
2.1、服务雪崩、容错方案
分布式系统面临许多问题,其中服务雪崩、容错都是常问到的问题。
分布式体系结构中的应用程序有很多依赖关系,每个依赖关系在某些时候将不可避免地失败。
2.1.1、服务雪崩
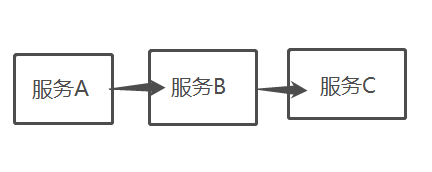
当服务A的流量突然增加,服务A扛得住请求,服务B和服务C未必能扛得住这突发的请求。
如果服务C因为抗不住请求,变得不可用。那么服务B的请求也会阻塞,慢慢耗尽服务B的线程资源,服务B就会变得不可用。紧接着,服务 A也会不可用
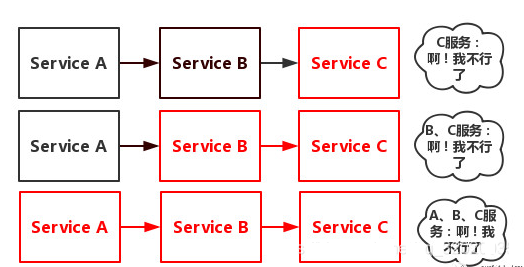
一个服务失败,导致整条链路的服务都失败的情形,我们称之为服务雪崩
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几秒钟内饱和,为了对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
2.1.2、容错方案
想要防止雪崩的扩散,就要做好服务的容错,容错说白了就是保护自己不被其他队友坑!那我们有哪些容错的思路呢?
1)隔离方案
它是指将系统按照一定的原则划分为若干个服务模块,各个模块之间相互独立,无强依赖。当有故障发生时,能将问题和影响隔离在某个模块内部,而不扩散风险,不涉及其他模块,不影响整体的系统服务。常见的隔离方式有:线程隔离 和信号量隔离:
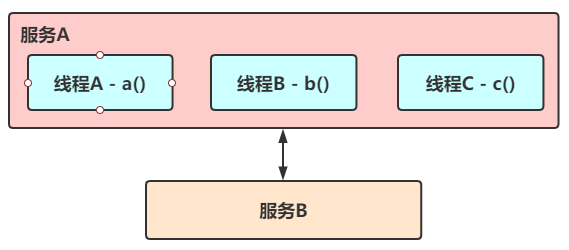
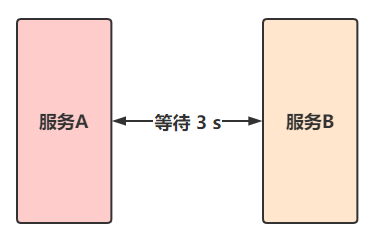
2)超时方案
在上游服务调用下游服务的时候,设置一个最大响应时间,如果超过这个时间下游服务还没响应,那么就断开连接,释放掉线程
3)限流方案
限流就是限制系统的输入和输出流量已达到保护系统的目的。为了保证系统的稳固运行,一旦达到需要限制的阈值,就需要限制流量并采用少量措施完成限制流量的目的
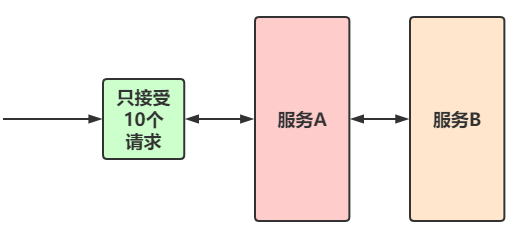
限流策略有很多:稍后我们详细介绍!
4)熔断方案
在互联网系统中,当下游服务因访问压力过大而相应变慢或失败的时候,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。这种牺牲局部,保全整体的措施就叫做熔断
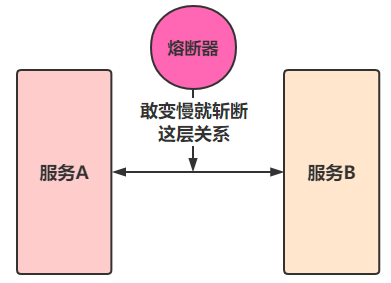
其中熔断有分为三种状态:
- 熔断关闭状态(Closed)
服务没有故障时,熔断器所处的状态,对调用方的调用不做任何限制
- 熔断开启状态(Open)
后续对该服务接口的调用不再经过网络,直接执行本地的 fallback 方法
- 半熔断状态(Half-Open)
尝试恢复服务调用,允许有限的流量调用该服务,并监控成功率。如果成功率达到预期,则说明服务已经恢复,进入熔断关闭状态;如果成功率依然很低,则重新进入熔断关闭状态
5)降级方案
降级其实就是为服务提供一个 B计划,一旦服务无法正常,就启用 B计划
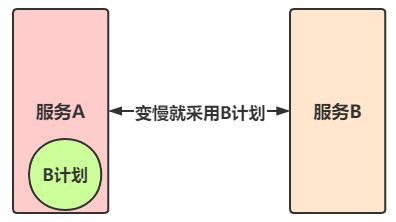
方案其实有很多,但是很难说明那种方案是最好的。在开发者的世界中,没有最好,只有最适合。那如果自己写一个容错方案往往是比较容易出错的(功力高深者除外),那么为了解决这个问题,我们不妨用第三方已经为我实现好的组件!
2.2. Sentinel 是什么?
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 的历史:
- 2012 年,Sentinel 诞生,主要功能为入口流量控制。
- 2013-2017 年,Sentinel 在阿里巴巴集团内部迅速发展,成为基础技术模块,覆盖了所有的核心场景。Sentinel 也因此积累了大量的流量归整场景以及生产实践。
- 2018 年,Sentinel 开源,并持续演进。
- 2019 年,Sentinel 朝着多语言扩展的方向不断探索,推出 C++ 原生版本,同时针对 Service Mesh 场景也推出了 Envoy 集群流量控制支持,以解决 Service Mesh 架构下多语言限流的问题。
- 2020 年,推出 Sentinel Go 版本,继续朝着云原生方向演进。
Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
Sentinel 可以简单的分为 Sentinel 核心库和 Dashboard。核心库不依赖 Dashboard,但是结合 Dashboard 可以取得最好的效果。
2.3. 基本概念及作用
基本概念:
资源:是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。在接下来的文档中,我们都会用资源来描述代码块。
只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则:围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
主要作用:
- 流量控制
- 熔断降级
- 系统负载保护
我们说的资源,可以是任何东西,服务,服务里的方法,甚至是一段代码。使用 Sentinel 来进行资源保护,主要分为几个步骤:
- 定义资源
- 定义规则
- 检验规则是否生效
先把可能需要保护的资源定义好,之后再配置规则。也可以理解为,只要有了资源,我们就可以在任何时候灵活地定义各种流量控制规则。在编码的时候,只需要考虑这个代码是否需要保护,如果需要保护,就将之定义为一个资源。
2.4. 快速开始
官方文档:https://github.com/alibaba/spring-cloud-alibaba/wiki/Sentinel
2.4.1. 搭建Dashboard控制台
您可以从 release 页面 下载最新版本的控制台 jar 包。
https://github.com/alibaba/Sentinel/releases
下载的jar包(课前资料已下发),copy到一个没有空格或者中文的路径下,打开dos窗口切换到jar包所在目录。
执行:java -jar sentinel-dashboard-xxx.jar
在浏览器中访问sentinel控制台,默认端口号是8080。
进入登录页面(http://localhost:8080/#/dashboard),
管理页面用户名和密码:sentinel/sentinel
此时页面为空,这是因为还没有监控任何服务。另外,sentinel是懒加载的,如果服务没有被访问,也看不到该服务信息。
2.4.2. 改造nacos-consumer
- 引入 sentinel 依赖
使用 group ID 为 com.alibaba.cloud 和 artifact ID 为 spring-cloud-starter-alibaba-sentinel 的 starter。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
- 在application.yml中添加配置
spring:
cloud:
sentinel:
transport:
dashboard: 192.168.188.138:8080
port: 8719
# 暴露/actuator/sentinel端点
management:
endpoints:
web:
exposure:
include: '*'
注意:必须暴露 /actuator/sentinel端点;(http://localhost:8000/actuator/sentinel)
重启nacos-consumer工程,在浏览器中反复访问:http://localhost:18080/hi
再次查看sentinel控制台页面:
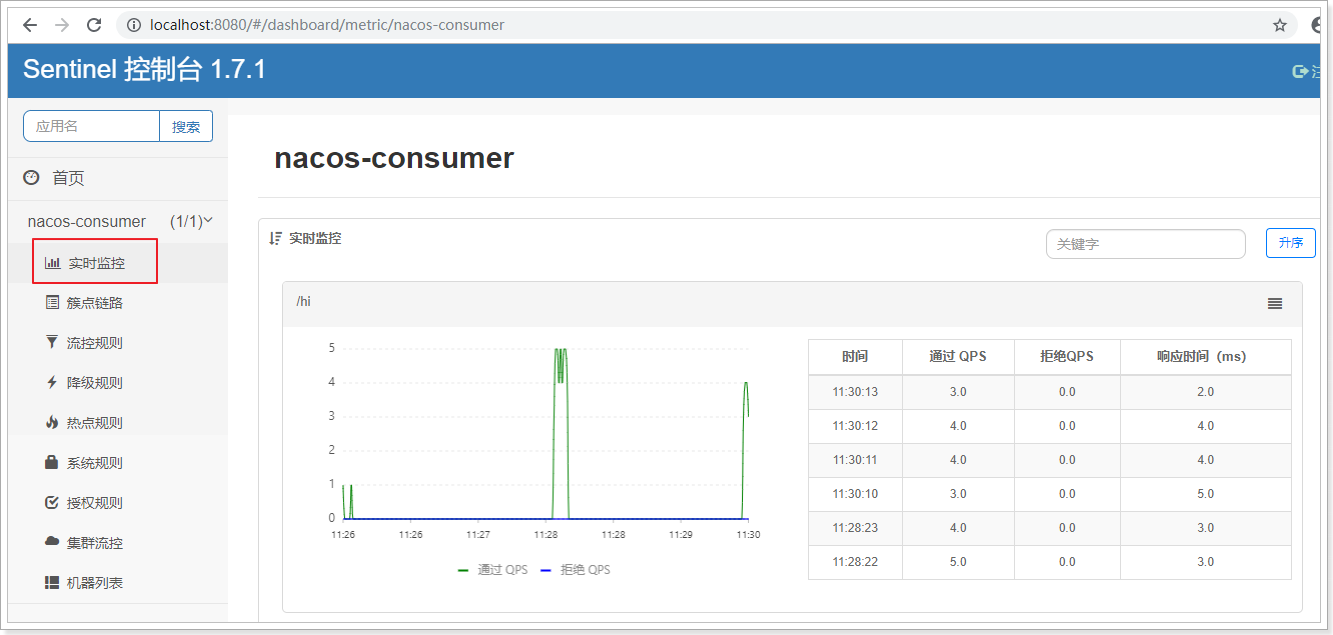
了解一下控制台的使用原理:
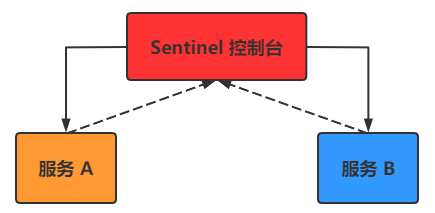
当 Sentinel应用启动后,我们需要将我们的微服务程序注册到控制台上,也就是在配置文件中指定控制台的地址,这个是肯定的。但是所谓用来跟控制台交流的端口,也就是我们每个服务都会通过这个端口跟控制台传递数据,控制台也可以通过此端口调用微服务中的监控程序来获取微服务的各种信息。
2.5. 整合Feign组件
Sentinel 适配了 Feign 组件。使用分三步:
- 引入依赖:
引入feign及sentinel的依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
注意:springCloud的版本兼容问题使用的是Hoxton.SR2 兼容的cloud alibaba版本是:2.2.0.RELEASE
注意:spring-cloud-starter-openfeign 2.2.6RELEASE 最高不能超过
- 开启sentinel监控功能
feign:
sentinel:
enabled: true
- 代码实现
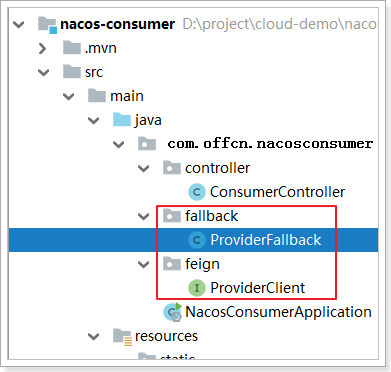
添加feign接口的熔断类ProviderFallback:
@Component
public class ProviderFallback implements ProviderClient {
@Override
public String hello() {
return "现在服务器忙,请稍后再试!";
}
}
在feign接口ProviderClient中指定熔断类:

测试之前,先在服务提供方的controller方法中添加异常:
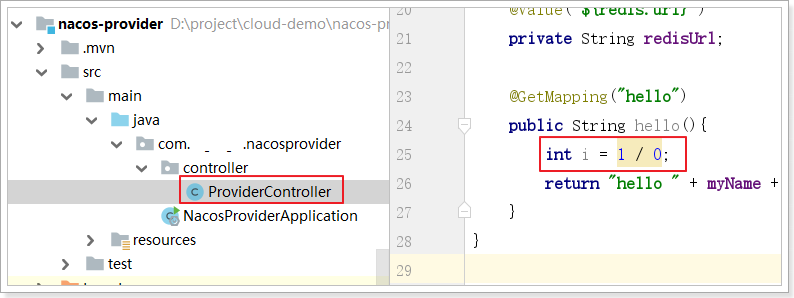
再重启nacos-provider和nacos-consumer服务。在浏览器中地址栏访问消费方测试:

2.6. 流量控制
2.6.1. 什么是流量控制
流量控制在网络传输中是一个常用的概念,它用于调整网络包的发送数据。然而,从系统稳定性角度考虑,在处理请求的速度上,也有非常多的讲究。任意时间到来的请求往往是随机不可控的,而系统的处理能力是有限的。我们需要根据系统的处理能力对流量进行控制。Sentinel 作为一个调配器,可以根据需要把随机的请求调整成合适的形状,如下图所示:
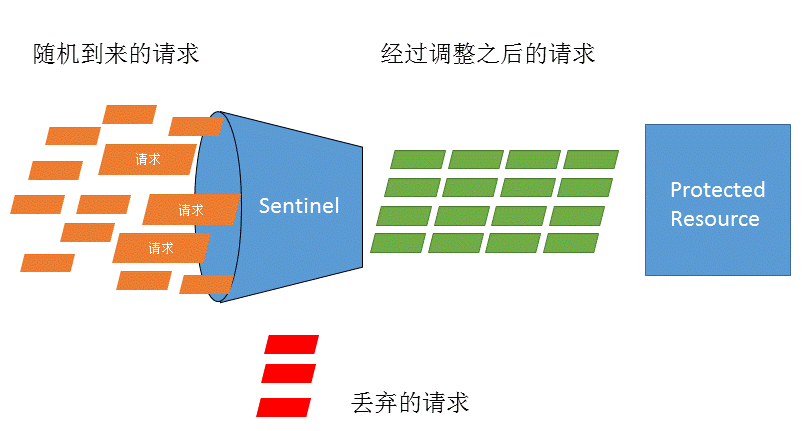 流量控制有以下几个角度:
流量控制有以下几个角度:
- 资源的调用关系,例如资源的调用链路,资源和资源之间的关系;
- 运行指标,例如 QPS、线程数等;
- 控制的效果,例如直接限流(快速失败)、冷启动(Warm Up)、匀速排队(排队等待)等。
Sentinel 的设计理念是让您自由选择控制的角度,并进行灵活组合,从而达到想要的效果。
配置如下:
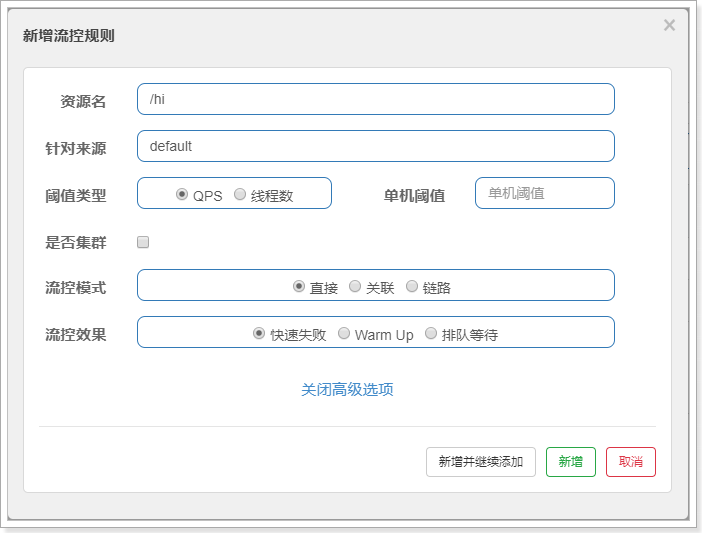
2.6.2. QPS流量控制
QPS:每秒钟处理请求次数.
当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的效果包括以下几种:直接拒绝、Warm Up、匀速排队。
2.6.2.1. 直接拒绝
直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。
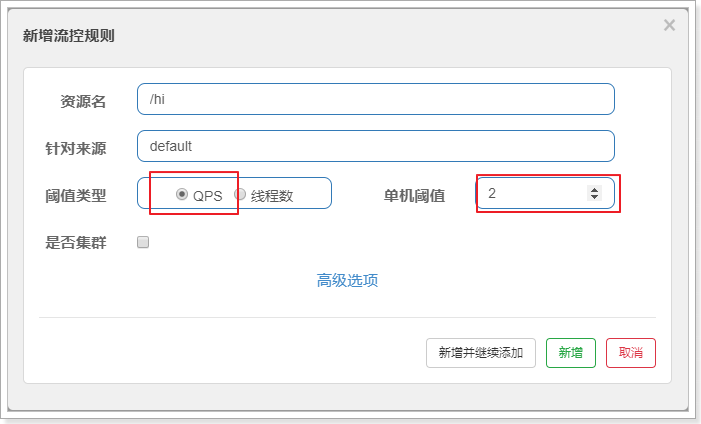
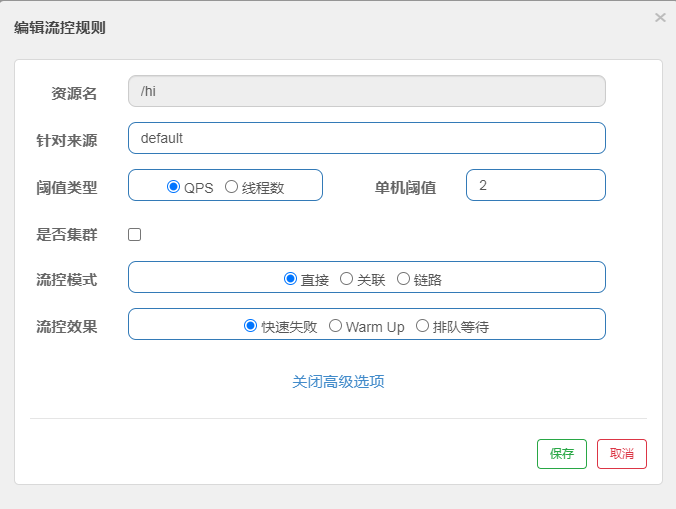
这里做一个最简单的配置:
阈值类型选择:QPS
单机阈值:2
综合起来的配置效果就是,该接口的限流策略是每秒最多允许2个请求进入。
点击新增按钮之后,可以看到如下界面:
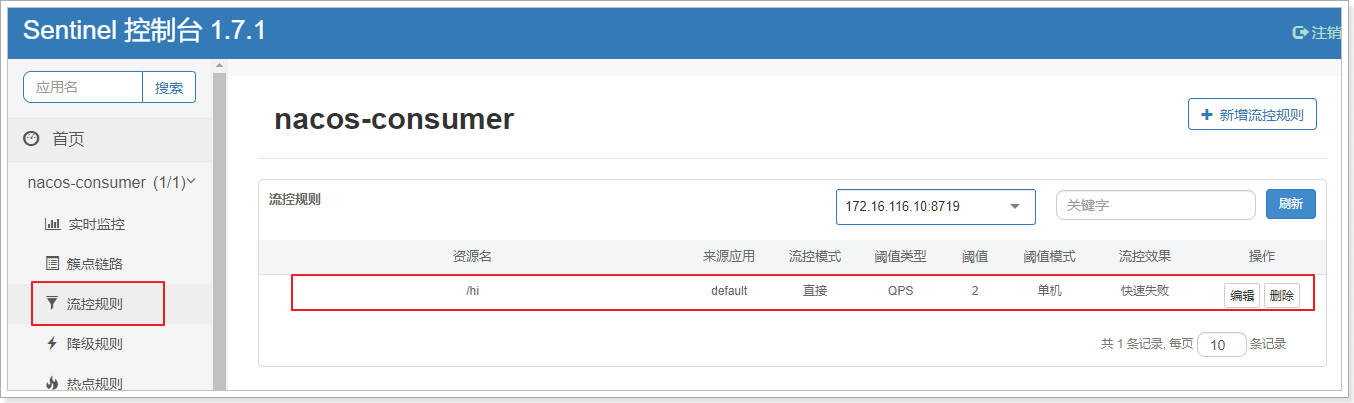
在浏览器访问:http://localhost:18080/hi,并疯狂刷新,出现如下信息:

2.6.2.2. Warm Up(预热)
Warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
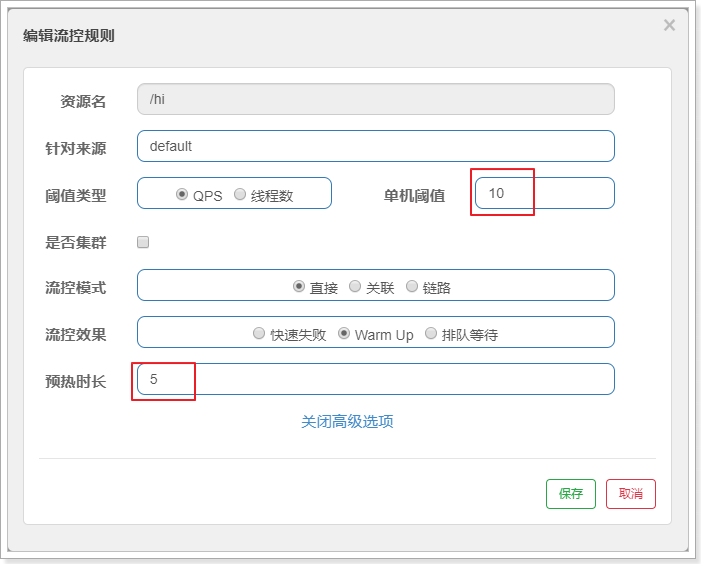
疯狂访问:http://localhost:18080/hi
 可以发现前几秒会发生熔断,几秒钟之后就完全没有问题了
可以发现前几秒会发生熔断,几秒钟之后就完全没有问题了
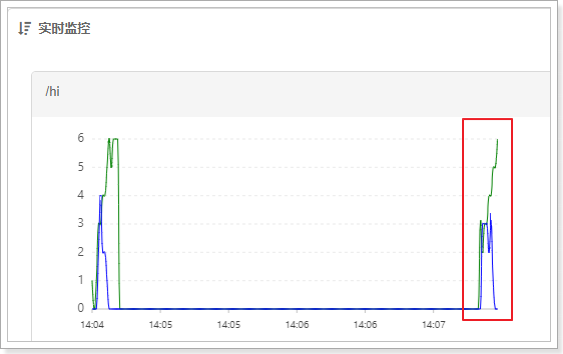
2.6.2.3. 匀速排队
匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
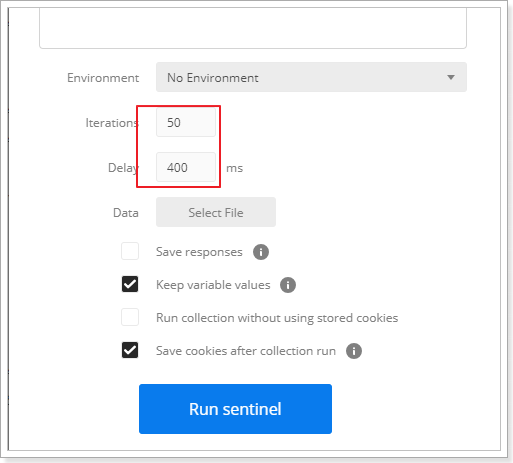
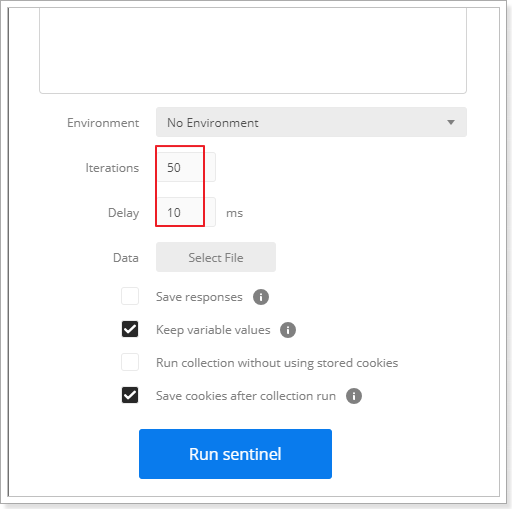
测试配置如下:1s处理一个请求,排队等待,等待时间20s。
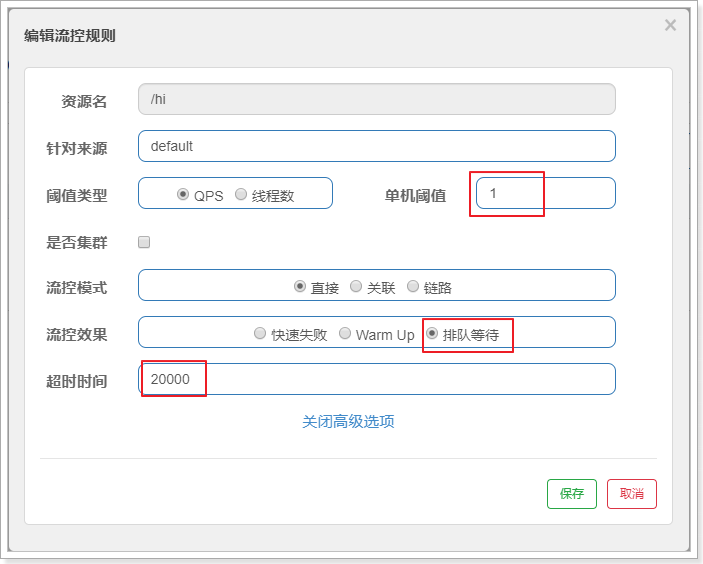
在postman中,新建一个collection(这里collection名称是sentinel),并把一个请求添加到该collection
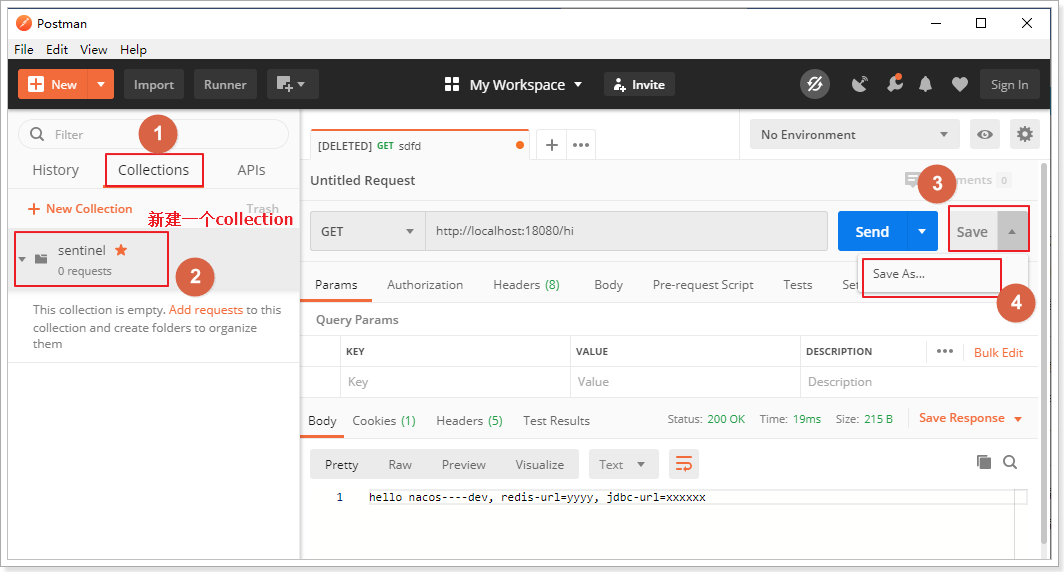
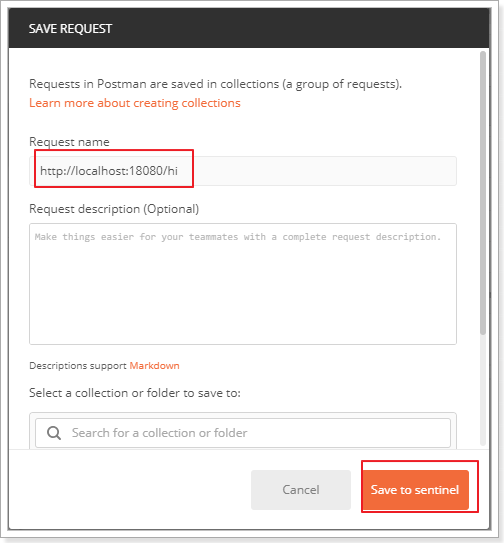
请求添加成功后,点击run按钮:
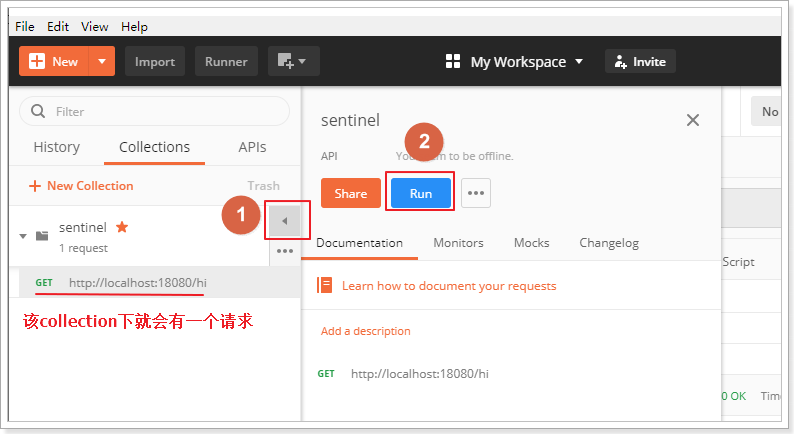
配置每隔100ms发送一次请求,一共发送20个请求:
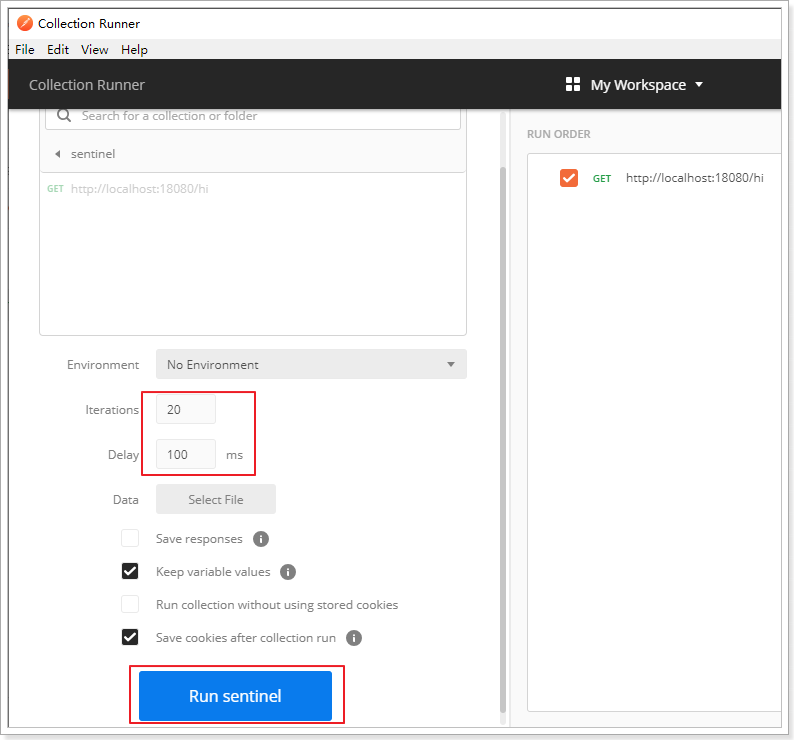
点击“run sentinel”按钮
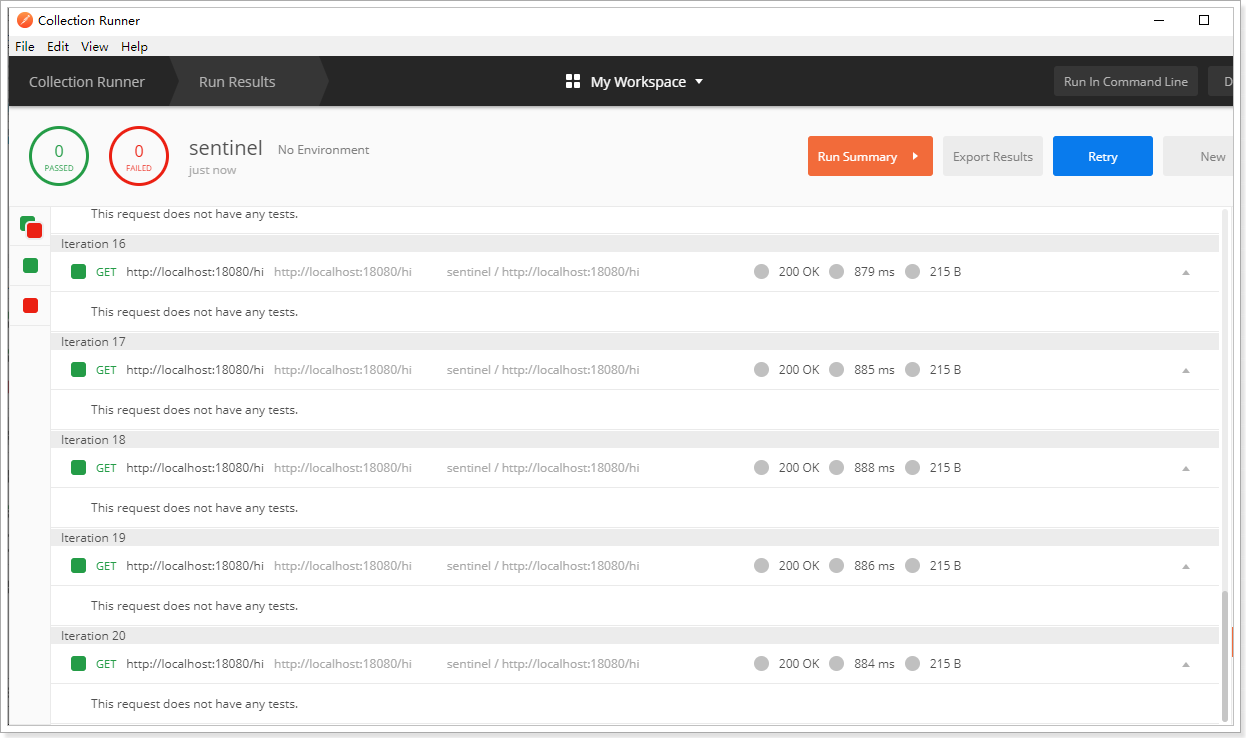
查看控制台,效果如下:可以看到基本每隔1s打印一次
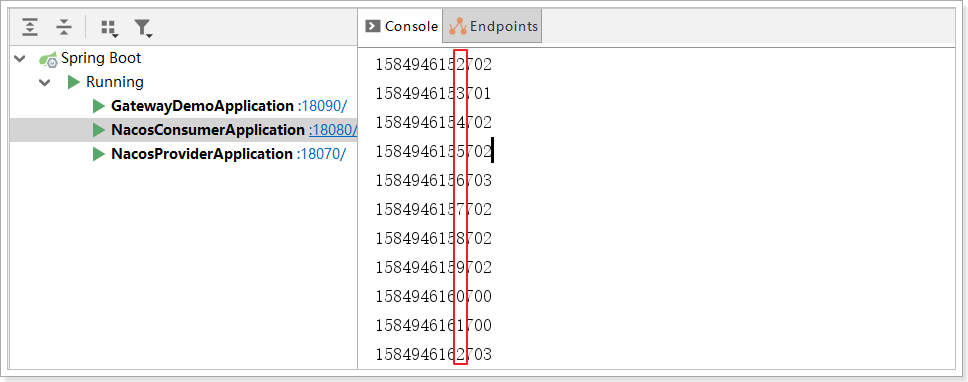
注意,在消费者打印当前毫秒值。System.out.println(System.currentTimeMillis());
2.6.3. 关联限流
关联限流:当关联的资源请求达到阈值时,就限流自己。
配置如下:/hi2的关联资源/hi,并发数超过/hi的限流时,/hi2就限流自己
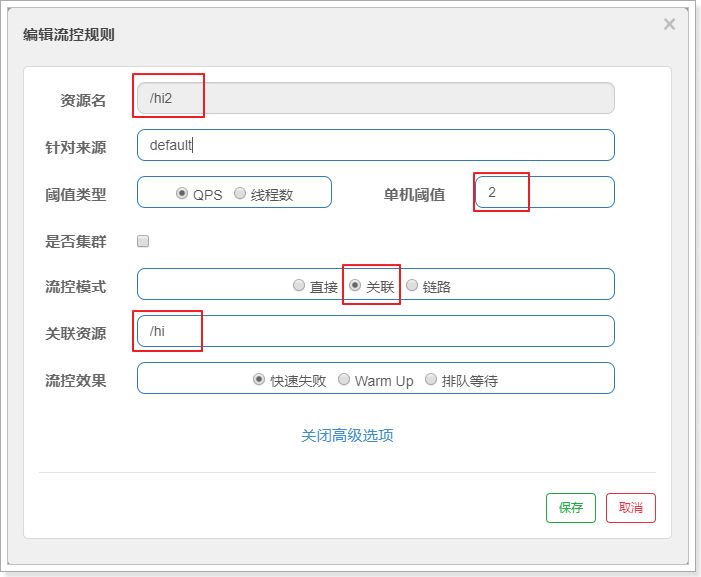
给消费者添加一个controller方法:
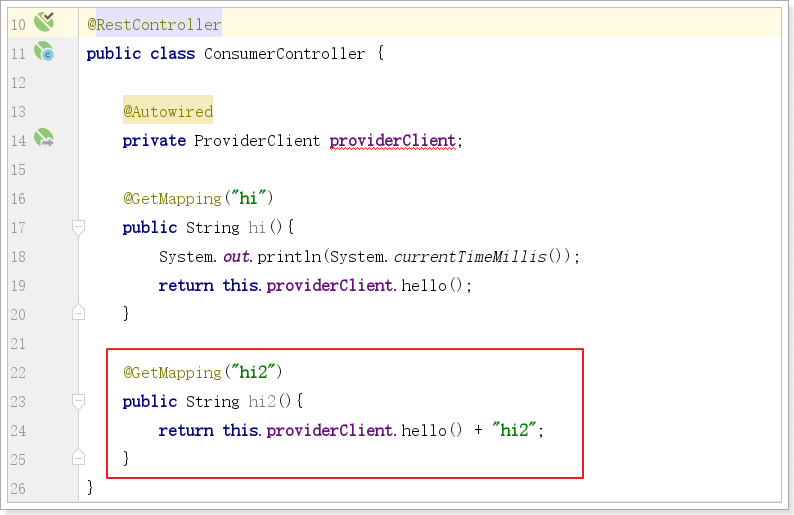
由于对/hi2的限流控制采用QPS关联,所以直接访问不会被限流,会发现一直刷新/hi2不会出现限流
测试访问/hi,超过限流阀值,在浏览器访问/hi2发现限流了:
postman配置如下:每个400ms发送一次请求,一共发送50个。每秒钟超过了2次
在浏览器中访问/hi2 已经被限流。

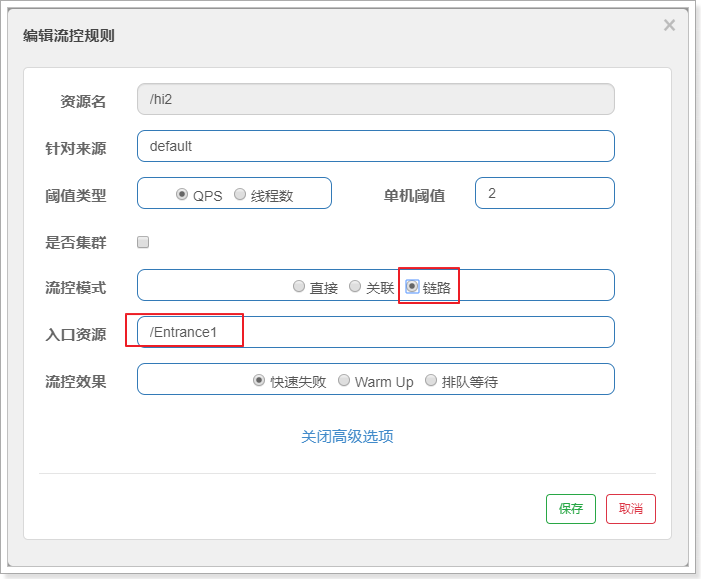
2.6.4. 链路限流
一棵典型的调用树如下图所示:
machine-root
/ \
/ \
Entrance1 Entrance2
/ \
/ \
DefaultNode(nodeA) DefaultNode(nodeA)
上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流。
配置如下:表示只针对Entrance1进来的请求做限流限制
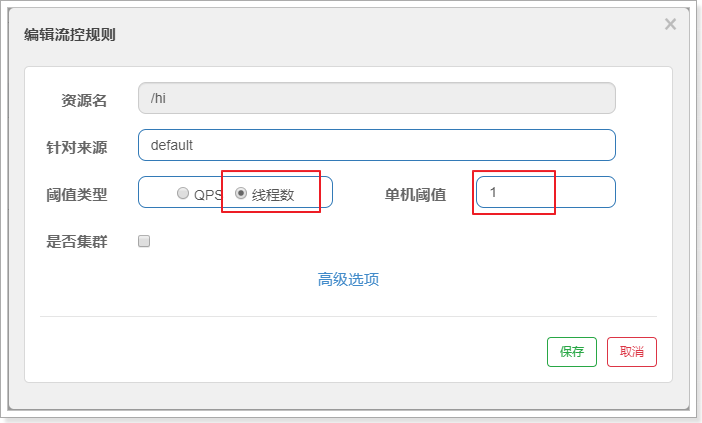
2.6.5. 线程数限流
**并发线程数限流用于保护业务线程数不被耗尽。**例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel 并发线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目,如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。
配置如下:如果请求的并发数超过一个就限流
改造controller中的hi方法:
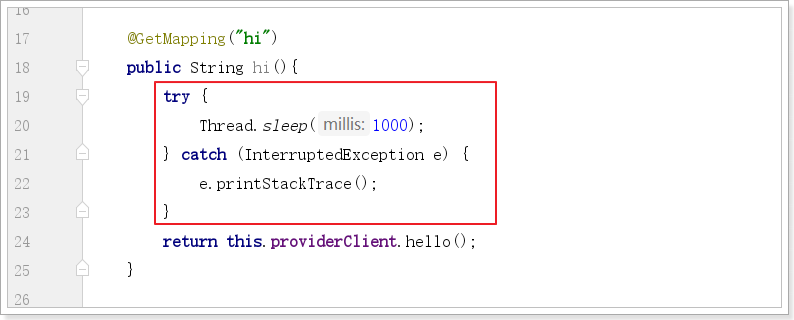
测试
postmain配置如下:
同时在浏览器访问:

2.7. 熔断降级
Sentinel除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
Sentinel 和 Hystrix 的原则是一致的: 当调用链路中某个资源出现不稳定,例如,表现为 timeout,异常比例升高的时候,则对这个资源的调用进行限制,并让请求快速失败,避免影响到其它的资源,最终产生雪崩的效果。
限流降级指标有三个,如下图:
-
平均响应时间(RT)
-
异常比例
-
异常数
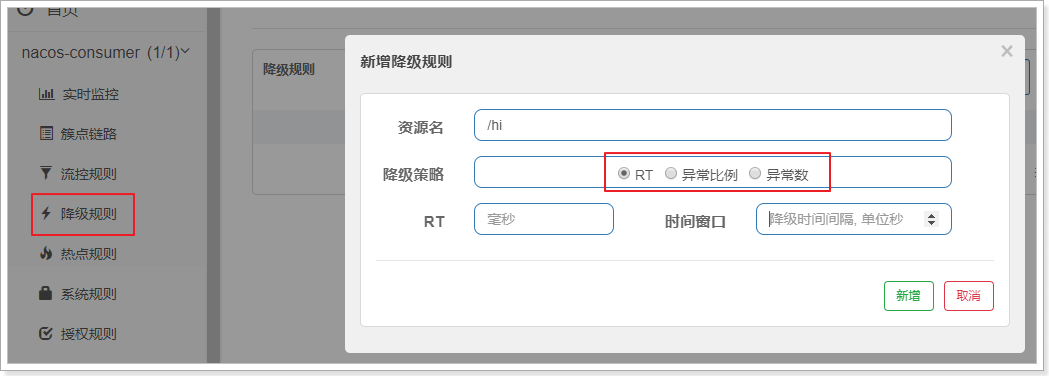
2.7.1. 平均响应时间(RT)
平均响应时间 (DEGRADE_GRADE_RT):当资源的平均响应时间超过阈值(DegradeRule 中的 count,以 ms 为单位,默认上限是4900ms)之后,资源进入准降级状态。如果1s之内持续进入 5 个请求,它们的 RT 都持续超过这个阈值,那么在接下来的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回(抛出 DegradeException)。在下一个时间窗口到来时, 会接着再放入5个请求, 再重复上面的判断。
配置如下:超时时间100ms,熔断时间10s
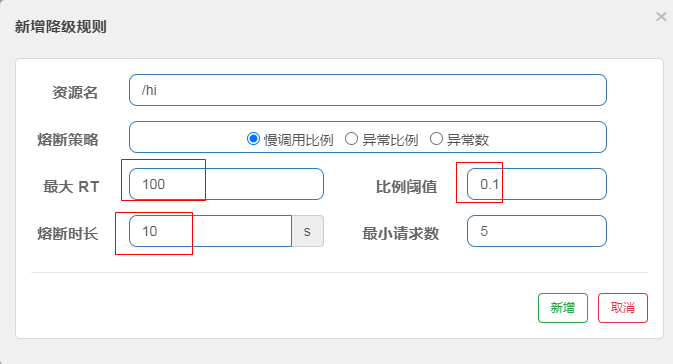
代码中依然睡了1s
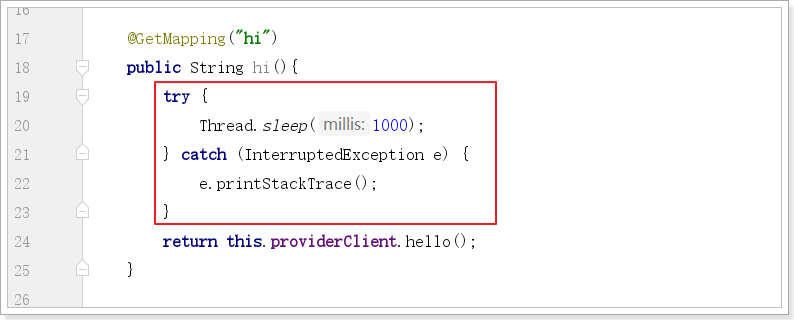
也就是说请求肯定都会超时。
先执行postmain,配置如下:
再次见到了熟悉的界面:

10s之内,都是熔断界面
2.7.2. 异常比例
异常比例 (DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= 5,且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
2.7.3. 异常数
异常数 (DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。
2.8. 规则持久化
无论是通过硬编码的方式来更新规则,还是通过接入 Sentinel Dashboard 后,在页面上操作更新规则,都无法避免一个问题,那就是服务重启后,规则就丢失了,因为默认情况下规则是保存在内存中的。
我们在 Dashboard 上为客户端配置好了规则,并推送给了客户端。这时由于一些因素客户端出现异常,服务不可用了,当客户端恢复正常再次连接上 Dashboard 后,这时所有的规则都丢失了,我们还需要重新配置一遍规则,这肯定不是我们想要的。
持久化配置分以下3步:
- 引入依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
- 添加配置:
spring:
cloud:
sentinel:
transport:
dashboard: 192.168.188.138:8080
port: 8719
datasource:
consumer:
nacos:
server-addr: 192.168.188.138:8848
dataId: ${spring.application.name}-sentinel-rules
groupId: SENTINEL_GROUP
data-type: json
rule_type: flow
- nacos中创建流控规则
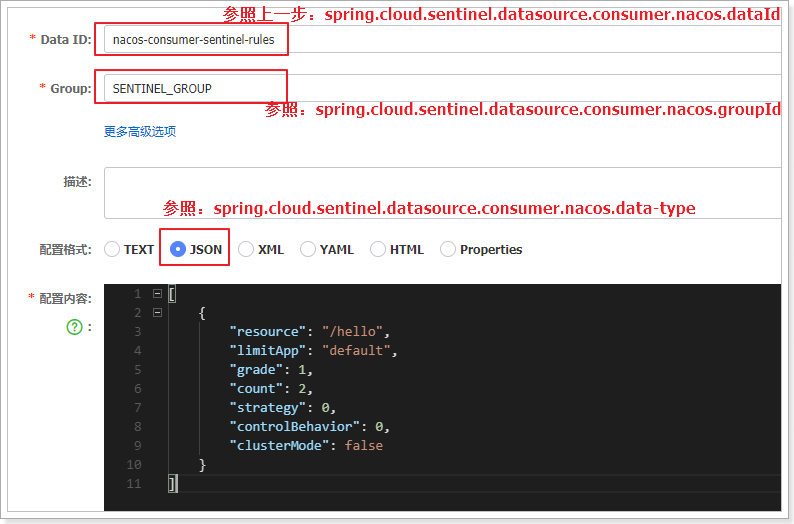
配置内容如下:
[
{
"resource": "/hi",
"limitApp": "default",
"grade": 1,
"count": 2,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
resource:资源名称
limitApp:限流应用,就是用默认就可以
grade:阈值类型,0表示线程数,1表示Qps
count:单机阈值
strategy:流控模式,0-直接,1-关联, 2-链路
controlBehavior:流控效果。0-快速失败,1-warm up 2-排队等待
clusterMode:是否集群
重启consumser,并多次访问:http://localhost:18080/hi。
查看sentinel客户端:就有了限流配置了
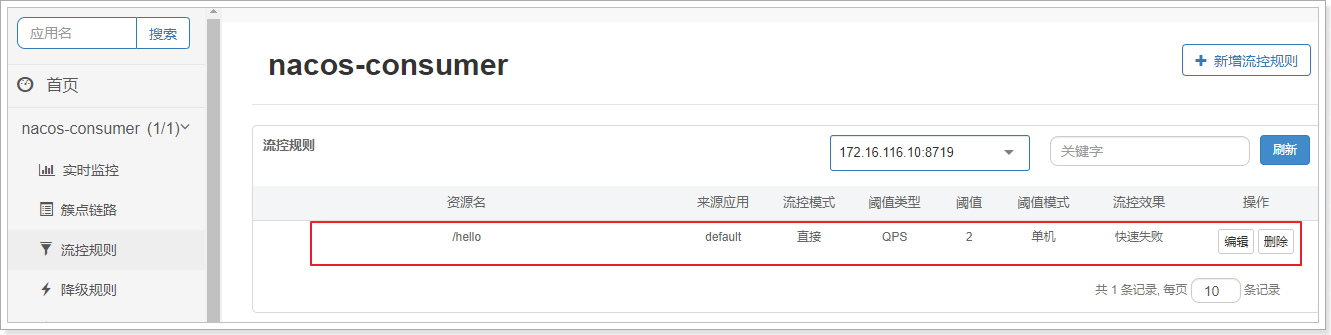
现在你可以尝试测试一下限流配置了
3. Sleuth
Spring Cloud Sleuth为springCloud实现了一个分布式链路追踪解决方案,大量借鉴了Dapper,Zipkin和HTrace等链路追踪技术。对于大多数用户而言,Sleuth应该是不可见的,并且您与外部系统的所有交互都应自动进行检测。您可以简单地在日志中捕获数据,也可以将其发送到远程收集器服务。
随着分布式系统越来越复杂,你的一个请求发过发过去,各个微服务之间的跳转,有可能某个请求某一天压力太大了,一个请求过去没响应,一个请求下去依赖了三四个服务,但是你去不知道哪一个服务出来问题,这时候我是不是需要对微服务进行追踪呀?监控一个请求的发起,从服务之间传递之间的过程,我最好记录一下,记录每一个的耗时多久,一旦出了问题,我们就可以针对性的进行优化,是要增加节点,减轻压力,还是服务继续拆分,让逻辑更加简单点呢?这时候springcloud-sleuth集成zipkin能帮我们解决这些服务追踪问题。
3.1. zipkin分布式监控客户端
Zipkin是一种分布式跟踪系统。它有助于收集解决微服务架构中的延迟问题所需的时序数据。它管理这些数据的收集和查找。Zipkin的设计基于Google Dapper论文。应用程序用于向Zipkin报告时序数据。Zipkin UI还提供了一个依赖关系图,显示了每个应用程序通过的跟踪请求数。如果要解决延迟问题或错误,可以根据应用程序,跟踪长度,注释或时间戳对所有跟踪进行筛选或排序。选择跟踪后,您可以看到每个跨度所需的总跟踪时间百分比,从而可以识别有问题的应用程序。
通过docker安装:docker run -d -p 9411:9411 openzipkin/zipkin
通过jar包安装:java -jar zipkin-server-*exec.jar
jar包下载地址:https://search.maven.org/remote_content?g=io.zipkin&a=zipkin-server&v=LATEST&c=exec
课前资料有已下载的jar包
在浏览器端访问:http://localhost:9411
3.2. 改造consumer/provider工程
对consumer和provider工程分别做如下操作:
- 引入sleuth的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
zipkin的启动器包含了sleuth的依赖。
- 配置zipkin的相关信息
spring:
zipkin:
base-url: http://192.168.188.138:9411
discovery-client-enabled: false
sender:
type: web
- 重启consumer/provider服务后,访问消费者:http://localhost:18080/hi。查看zipkin客户端如下
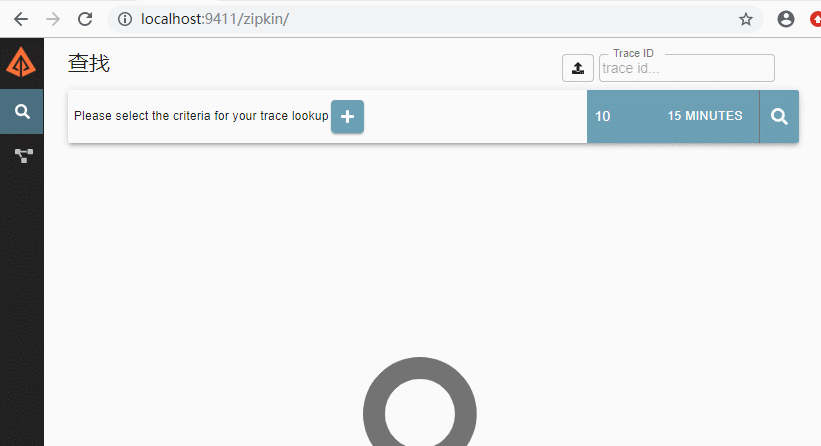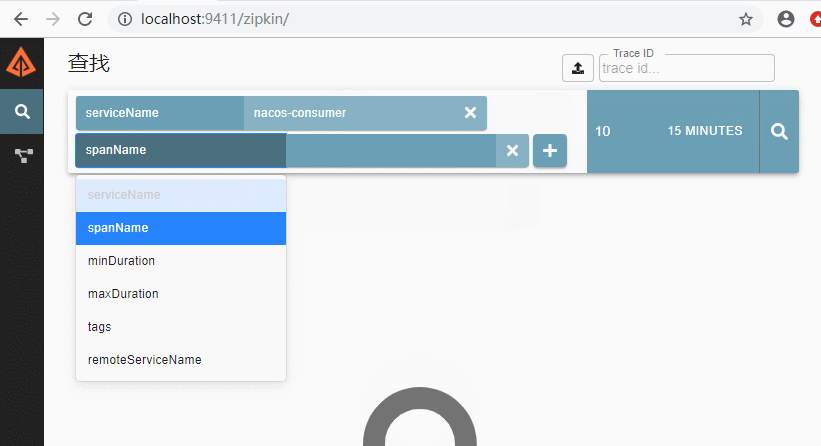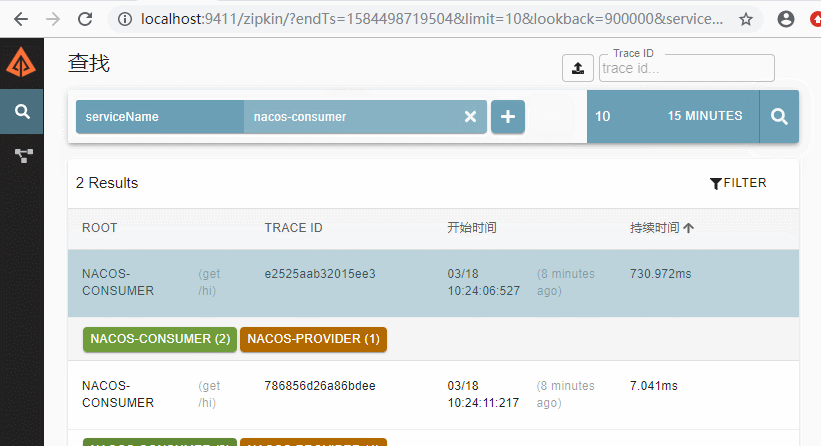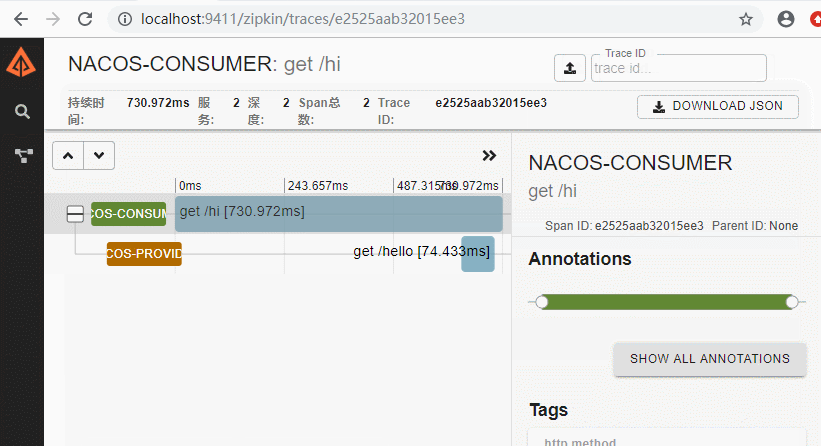 这时候我们可以在zipkin的ui控制界面看看效果,可以发现,服务之间的调用关系,服务名称已经清晰展现出来了,同时包括服务之间的调用时常等详细信息以及更细的信息都可以通过控制台看到。
这时候我们可以在zipkin的ui控制界面看看效果,可以发现,服务之间的调用关系,服务名称已经清晰展现出来了,同时包括服务之间的调用时常等详细信息以及更细的信息都可以通过控制台看到。
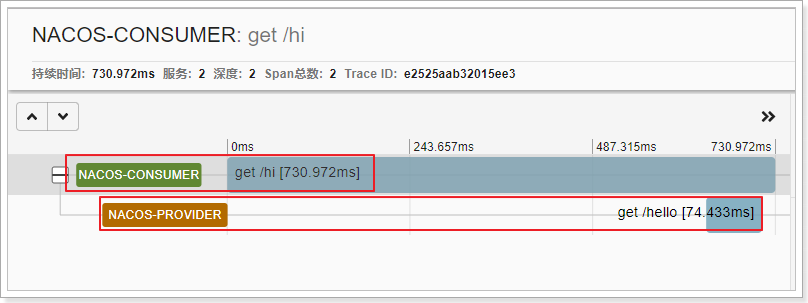
还可以查看调用关系图:
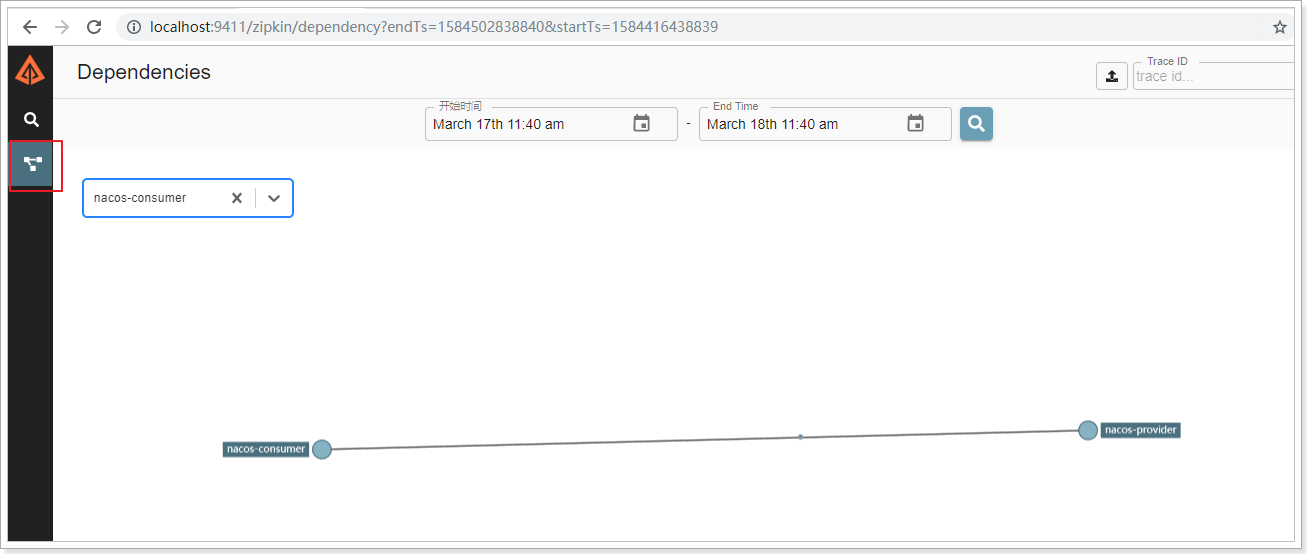
3.3. 基本概念
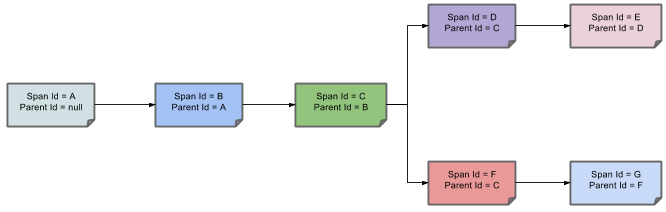
Span:基本工作单元。发送一个远程请求就会产生一个span,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址)。span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
Trace:一系列spans组成的一个树状结构。例如:发送一个请求,需要调用多个微服务,每调用一个微服务都会产生一个span,这些span组成一个trace
Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
例如一个请求如下:

使用zipkin跟踪整个请求过程如下:
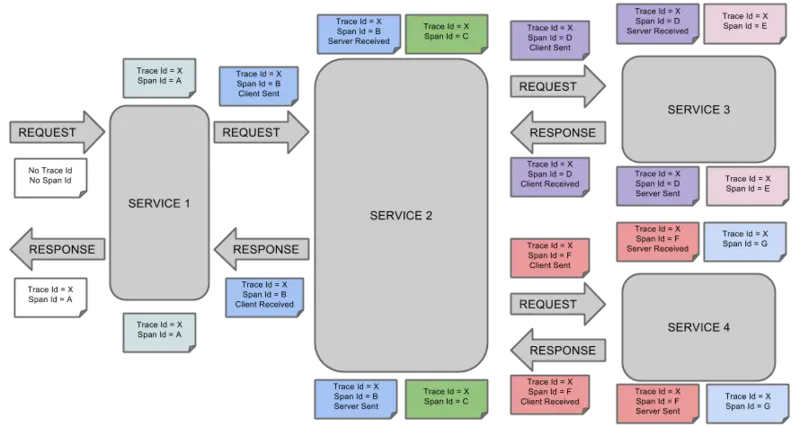 上图表示一请求链路,一条链路通过
上图表示一请求链路,一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来,如图